第一章 Oracle 的并行
并行执行:同时开启多个进程/ 线程来完成同一个任务。 本质:以额外的硬件资源消耗来换取执行时间的缩短 额外硬件资源消耗:对数据库服务器上的多个CPU 、内存、多个 I/O 通道,甚至是RAC 环境下多个数据库节点的额外利用。
1.1 Oracle 里可以使用并行的场景
1 、并行查询 执行查询时,查询所需要做的工作如果能被分割成多个互不相关的部分,那么该查询语句就可以由多个进程同时并发执行。 并行查询包括: 全表扫描 快速索引全扫描 分区索引范围扫描 执行了全表扫描的表连接(hash ,sort merge ,nl) 2 、并行DDL : create table as select create index rebuild index rebuild index partition move / split /coalesce partition 3 、并行DML insert as select update delete merge 4 、并行数据加载 SQL * loader 导入文本数据 5 、并行备份和恢复 6 、并行收集统计信息
1.2 什么时候使用并行
常见的场景:
1、 普通SQL 最常见的情况就是大表的全表扫描,还有就是大的索引的快速全扫描(注意:只有index fast full scan 可以使用并行,index full scan 和index range scan 都不可以使用并行)
2、 使用并行的误区:
SQL 执行慢的时候,不是直接使用并行或者增加并行度来提高SQL 的执行速度。
SQL 使用并行,需要看SQL 的执行计划,如果确实可以使用并行操作来提高执行速度,那么可以选择考虑使用并行;相反,例如SQL 中使用标量子查询,并且标量子查询里的连接字段没有索引,那么即使使用了并行,也是无法提升很大的速度,若使用DB link ,那么使用并行也是不起用的。
3、 多大的表算大表
百万行记录以上的表都可以算在大表范围内。
如果是几亿甚至十几亿的行记录的大表的全表扫描的SQL 会执行时间会很长,但是如果使用并行的话(满足使用并行的前提),执行效率会有提升。
4、 使用create table as select 的方式创建一张表
CREATE TABLE TEST AS SELECT T1.COL1,T2.COL2,...TN.COL2 FROM T1,T2,...,TN WHERE T1.COL1 = T2.COL1 AND ...
这时候创建一张大表test ,那么会很慢,但是可以考虑在创建表的时候使用并行,DDL 的并行。
创建完毕后需要关闭表的并行。
ALTER TABLE TEST NOPARALLEL ;
CREATE TABLE TEST1 PARALLEL 8 AS SELECT T1.OBJECT_ID,T2.OWNER FROM T1,T2 WHERE T1.OBJECT_ID = T2.OBJECT_ID;
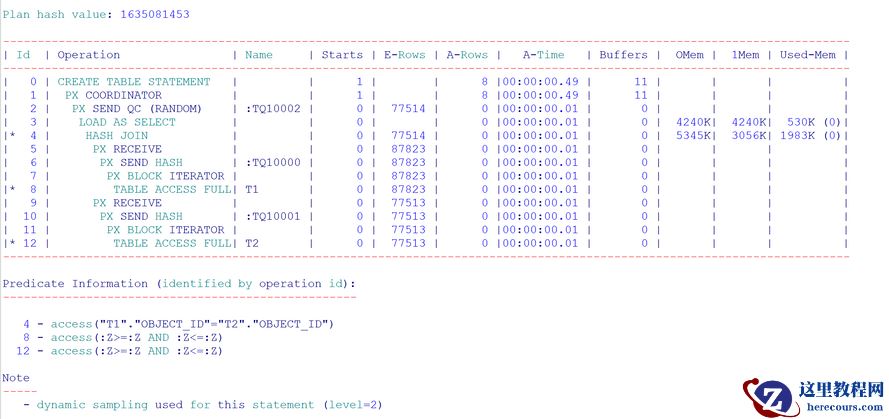
CREATE TABLE TEST3 AS SELECT /*+PARALLEL 8 */T1.OBJECT_ID,T2.OWNER FROM T1,T2 WHERE T1.OBJECT_ID = T2.OBJECT_ID;
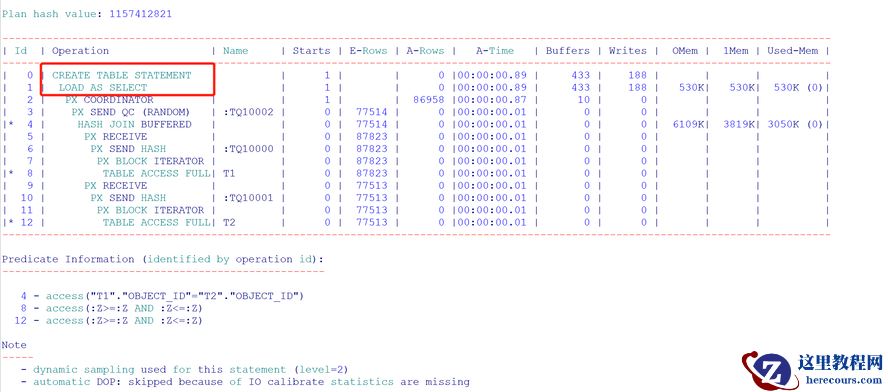
创建表的四种情况:
① CREATE TABLE TEST AS SELECT T1.OBJECT_ID,T2.OWNER FROM T1,T2 WHERE T1.OBJECT_ID = T2.OBJECT_ID;
② CREATE TABLE TEST1 PARALLEL 8 AS SELECT T1.OBJECT_ID,T2.OWNER FROM T1,T2 WHERE T1.OBJECT_ID = T2.OBJECT_ID;
③ CREATE TABLE TEST2 PARALLEL 8 AS SELECT /*+PARALLE 8 */T1.OBJECT_ID,T2.OWNER FROM T1,T2 WHERE T1.OBJECT_ID = T2.OBJECT_ID;
④ CREATE TABLE TEST3 AS SELECT /*+PARALLEL 8 */T1.OBJECT_ID,T2.OWNER FROM T1,T2 WHERE T1.OBJECT_ID = T2.OBJECT_ID;
第一种方式是正常的创建表,查询部分是串行查询,create 插入时也是串行插入;
第二种方式在create as 之间使用并行,会使得整个过程都是并行,查询部分和插入部分都是并行的操作;
第三种方式是在create as 之间使用并行和后面的查询部分使用select ,其实这个写法和在create as 之间使用并行等价,因此DDL 的并行,只需要在DDL 语句中间使用并行;
第四种写法是在查询部分使用并行,只在查询的部分用并行,在插入的部分还是使用串行。
注意:
在使用并行创建表,需要对表关闭并行。
5、 创建或者重建索引
CREATE INDEX IDX_TEST ON TEST(ID) PARALLEL 8;
ALTER INDEX IDX_TEST NOPARALLEL;
在使用并行创建完索引后,需要对索引进行关闭并行操作,否则在之后的每次查询(索引快速全扫描),都会对该索引使用并行。
例子:
使用并行创建索引
create table demo as select * from dba_objects;
create index idx_id_demo on demo(object_id) parallel 8;
查看当前索引的并行度:

当前索引的并行度为8
查询:
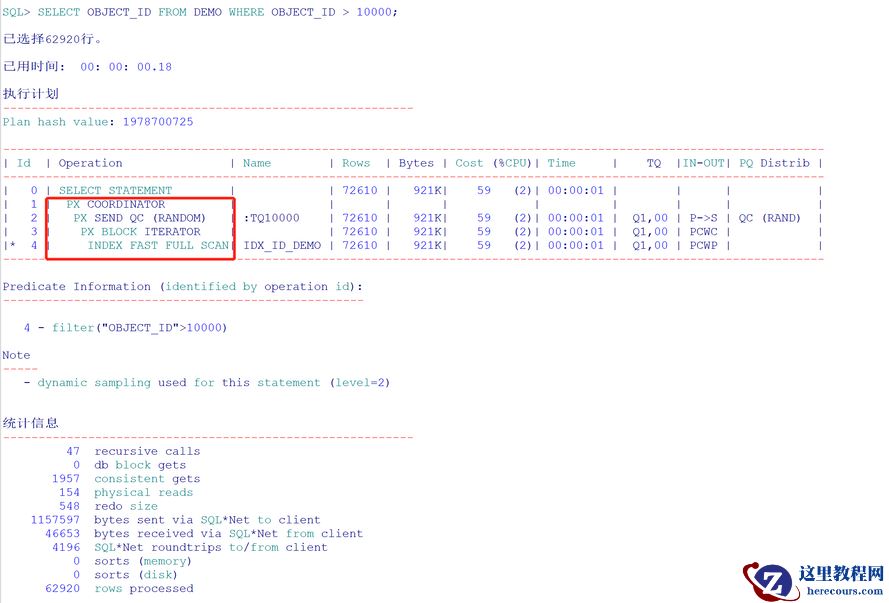
通过执行计划可以看到,使用了索引快速全扫,并且还是并行的索引快速全扫.
关闭索引的并行:
ALTER INDEX IDX_ID_DEMO NOPARALLEL;
再次查看当前索引的并行度:

当前索引的并行度变为1 (表和索引的默认并行度为1 )
再次查询:
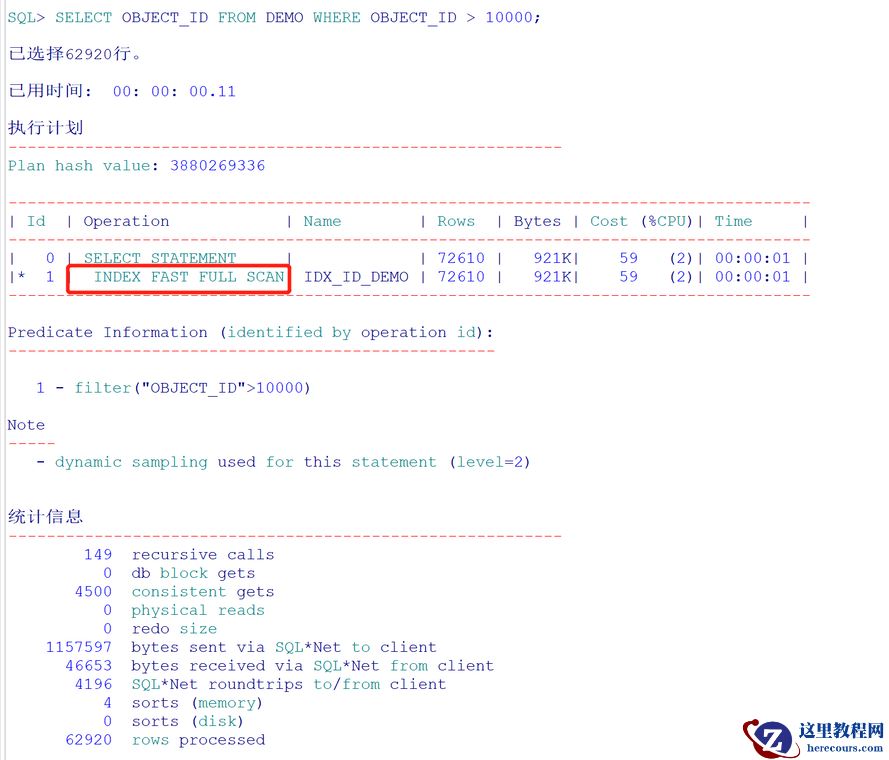
执行计划中不再有并行,只有索引快速全扫。
注意:
如果在创建索引时使用了并行,一定要记得关闭并行 。
索引的并行hint 的写法:parallel_index(table_name index_name n) 。
6、 大表收集统计信息也可以使用并行。
7、 DML 语句的并行
在使用DML 语句时, 有需要并行的时候在关键字后面加并行。
INSERT 、DELETE 、UPDATE 、MERGE
使用insert 的时候:
INSERT /*+ PARALLEL(8) */INTO T1 SELECT … FROM …
这种写法会对SQL 执行时使用并行操作,但是需要注意的是,这样的并行只是在select 查询部分使用了并行,在插入部分还是串行,DML 部分并没有使用并行,当数据量大时,串行的插入依旧很慢;DML 的并行是默认关闭的,如果需要使用DML 的并行,那么需要在会话开启并行的DML 。
ALTER SESSION ENABLE PARALLEL DML
然后执行带有并行的SQL 语句;
然后关闭会话的DML 并行
ALTER SESSION DISABLE PARALLEL DML
或者使用以下的方法:
在会话级别使用指定DML 的并行度(force )
ALTER SESSION FORCE PARALLEL DML PARALLEL 8
执行SQL (不需要带有并行的hint ),这时候DML 的操作将变为并行操作。
关闭DML 的并行
ALTER SESSION DISABLE PARALLEL DML
或者
ALTER SESSION FORCE PARALLEL DML PARALLEL 1
开启了DML 的并行后,接下来的DML 的SQL 将会产生一个表锁,在commit 之前,当前会话不能对该表做查询和DML 操作,其他会话不能对该表做DML 操作。
建议:
并行的DML ,需要在执行完SQL 后,立即commit ,然后关闭DML 的并行。
完整过程
① ALTER SESSION ENABLE PARALLEL DML
或者ALTER SESSION FORCE PARALLEL DML PARALLEL 8
② 执行带有并行hint 的SQL
或者执行不带有hint 的SQL (前提是指定了DML 的并行度)
③ 关闭DML 并行
ALTER SESSION DISABLE PARALLEL DML
或者
ALTER SESSION FORCE PARALLEL DML PARALLEL 1
1.3 并行Hint 的写法
通常我们会使用hint 在SQL 级别设置并行,一般不在表和索引上设置并行度。 在创建表或者创建索引时使用了并行create table test parallel 8 as select … from …create index idx_id_test on test(id) parallel 8 都需要在创建完成后关闭并行alter table test noparallel 或者alter table test parallel 1 alter index idx_id_test noparallel 或者alter index idx_id_test parallel 1 在关键字中写并行的hint :
① 对SQL 中的每个表都使用并行则可以使用简单写法
select /*+ parallel(8) */…from t1,t2…
使用这种写法,简洁,不会出现遗漏,因为这样写会让SQL 中出现的表都使用并行的操作(如果优化器认为并行效率更高,而不是把所有的表一定并行扫描)
② 在hint 中具体的指明某个表或者某个索引使用并行
select /*+ parallel(a 4) parallel(b 4) */ … from t1,t2…
使用这种写法比较清楚对哪些表或者索引使用并行,但是hint 可能会很长,而且当SQL 中涉及的表多,并且含有大表的时候,如果有遗漏表,那么这个表将使用串行的方法去扫描,会造成性能问题。
注意:
对于两种写法来说,各有各的好处:
对于第一种写法来说,写法简洁,但是不指明哪些表或者索引使用并行,那么会存在只要是有全表扫描的情况,那么很有可能会把这些表的操作都变成并行操作,当同时存在高并发的时候则会立即消耗完系统的资源。
对于第二种来说,写的表或者索引较多,并且会出现遗漏,但是可以确定是某些表使用了并行,不会对全部的表进行并行操作,同时有大量并发时,可以用时间去换取资源。
总的来说,使用哪种情况需要根据SQL 中的表的情况和执行计划的情况,不能直接就写死并行(不考虑表的情况),当有大量并发时会消耗完资源;最可取的办法是一个表一个表的分析,然后确定使用并行,并且使用多少的并行度。
1.4 并行的使用
1.4.1 查询时表使用并行
表上无索引:select count(*) from demo t1,test t2 where t1.object_id = t2.object_id;
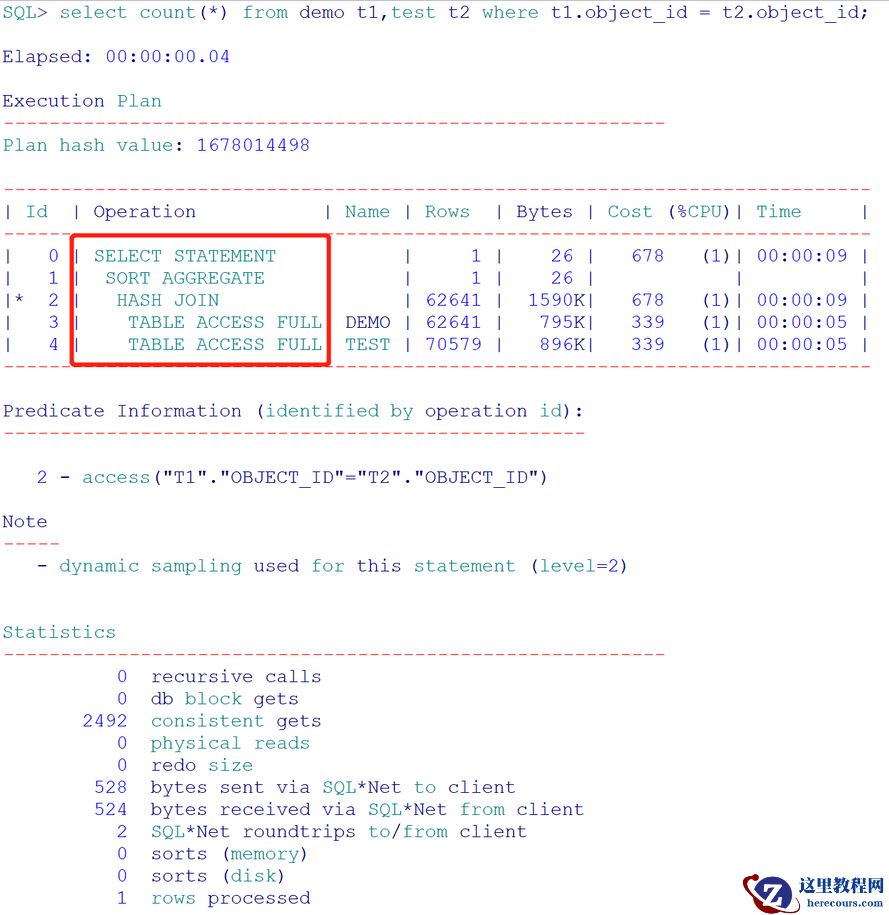 两个表都是全表扫描,并且都是串行扫描
两个表都是全表扫描,并且都是串行扫描
1、 写出具体的表
select /*+ parallel(t1 8) */count(*) from demo t1,test t2 where t1.object_id = t2.object_id;
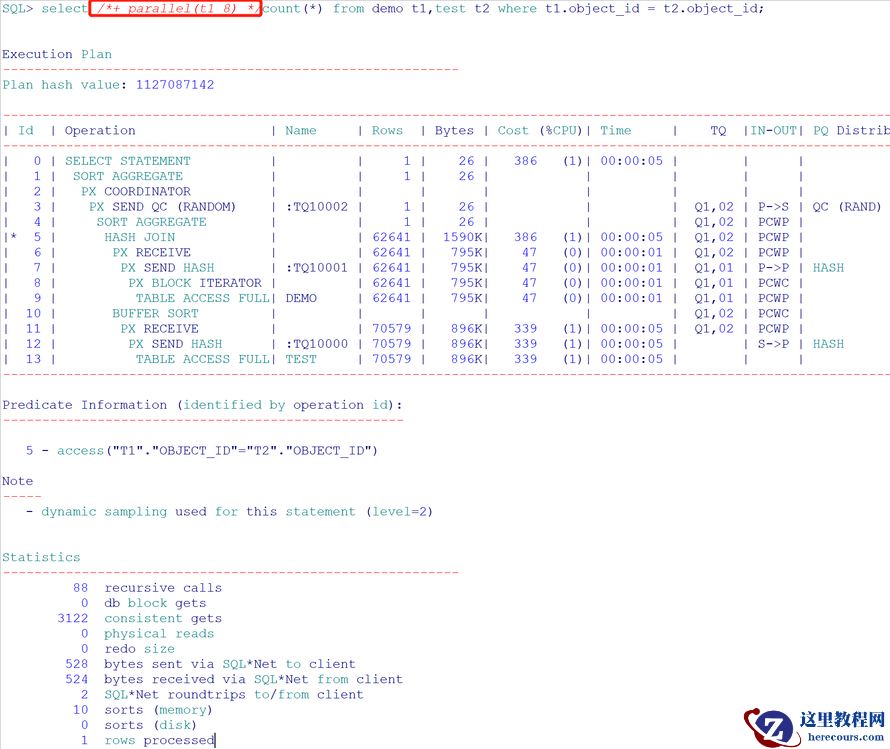
对t1 表指定并行,那么只会对demo 使用并行,其他的表都是串行
2、 不写具体的表
select /*+ parallel(8) */count(*) from demo t1,test t2 where t1.object_id = t2.object_id;
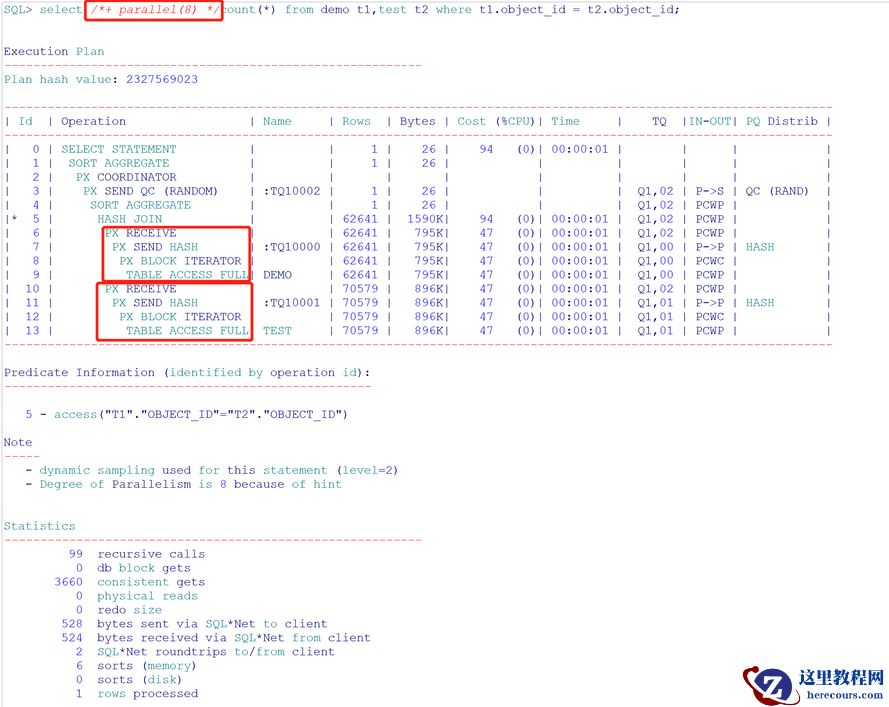
不写出具体的表,那么会造成对SQL 中所有的表都使用并行。
1.4.2 查询时索引使用并行
在使用并行的时候说过,只有全表扫描和索引快速全扫可以使用,因此只有当索引快速全扫的使用并行才启用。
在demo
表的id
字段建立索引create index idx_id_demo on demo(object_id)
查询:select object_id from demo where object_id > 1000;
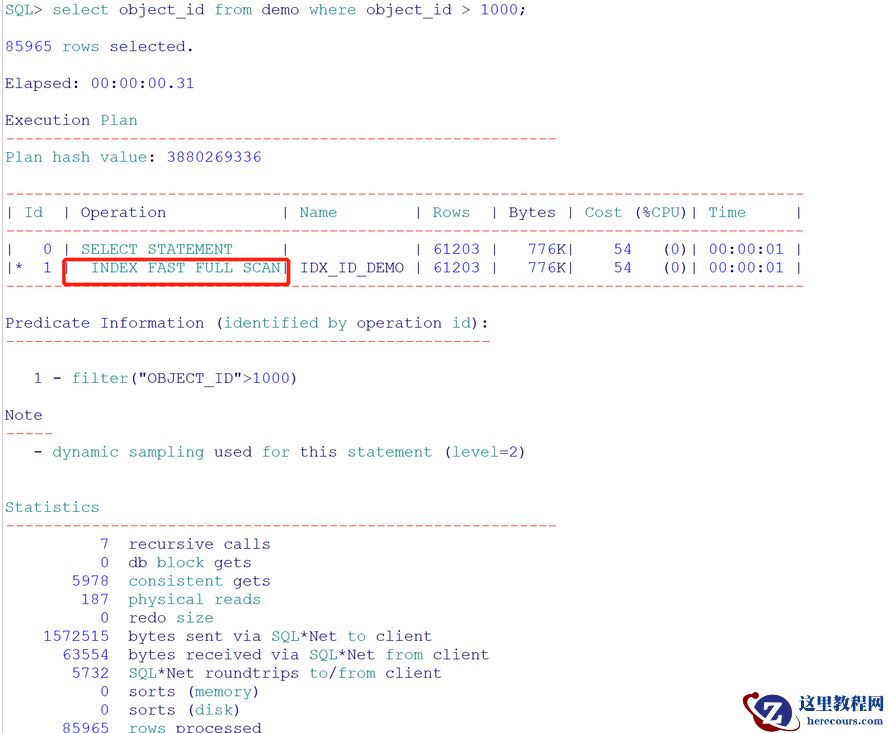 现在使用索引快速全扫,因此可以使用并行(注意,并不是看见了索引快速全扫就用并行)
错误写法select /*+ index(idx_id_demo 8) */object_id from demo where object_id > 1000;
或者select /*+ index(demo idx_id_demo 8) */object_id from demo where object_id > 1000;
以上两种写法都不会对索引使用并行。
现在使用索引快速全扫,因此可以使用并行(注意,并不是看见了索引快速全扫就用并行)
错误写法select /*+ index(idx_id_demo 8) */object_id from demo where object_id > 1000;
或者select /*+ index(demo idx_id_demo 8) */object_id from demo where object_id > 1000;
以上两种写法都不会对索引使用并行。
 正确写法:
需要使用parallel_index(table_name index_name n)select
/*+ parallel_index(demo idx_id_demo 8) */object_id from demo where object_id > 1000;
正确写法:
需要使用parallel_index(table_name index_name n)select
/*+ parallel_index(demo idx_id_demo 8) */object_id from demo where object_id > 1000;
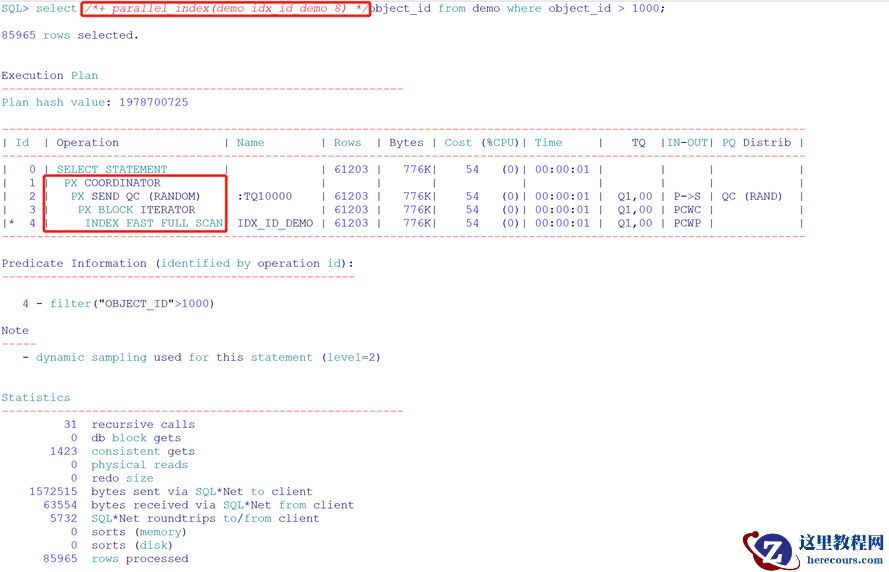 可以看到索引快速全扫使用了并行。
在使用索引快速全扫的时候,需要注意是否要使用并行,以及写hint
的方式,其中parallel_index(table_name index_name n)
每个参数间可以使用空格,也可以使用逗号隔开,这在hint
的参数中是通用的。
可以看到索引快速全扫使用了并行。
在使用索引快速全扫的时候,需要注意是否要使用并行,以及写hint
的方式,其中parallel_index(table_name index_name n)
每个参数间可以使用空格,也可以使用逗号隔开,这在hint
的参数中是通用的。
第二章 总结
1、 在大部分的场景都可以使用并行,增删改查都可以使用并行,需要注意DML 的并行和查询的并行的正确写法。
2、 使用hint 写并行的时候,需要考虑表的具体的情况,不能直接就写死了并行,以免造成不必要的资源消耗。
3、 DDL 使用并行时,并行建表和建索引的时候,创建完之后,立即关闭表或者索引的并行,需要使用并行时,在SQL 中去使用,不在对象上设置并行度。
4、 开启会话的DML 并行后,执行完SQL 后,立即提交,然后关闭DML 的并行,以免造成大量的锁等待。
5、 在写具体的表的并行时/*+ parallel(a 4) */ ,会出现hint 失效,为确保hint 可以正确使用,可以加上full 字样,/*+ full(a) parallel(a 4) */ 。
6、 索引的并行时,使用parallel_index(table_name index_name n) 字样,需要满足索引快速全扫的前提,并且需要进一步分析是否应该使用索引快速全扫的并行。
7、 对于提到的表的情况,并不是指这个表内具体有多少数据,比如一个表有1 亿行记录,返回一行数据,那么肯定是不能用并行的,效率最高的肯定是索引;一个表只有100 万行,但是返回了20 万行记录,那么用索引肯定效率低,可以考虑并行;总的来说,表的分析是指经过where 条件过滤后返回的记录,如果返回的数据很少,哪怕表的数据量很大,那么都适合使用索引,如果表的记录数相对不大,返回的记录数多,那么可以考虑使用并行的全表扫描。











