接到一个朋友数据库故障请求case.大概操作是这样的:有一个39T的lun,通过parted分了15个分区,给oracle asm使用创建磁盘组data4,然后分了4个分区做成data5(由于ausize写错误了),删除掉磁盘组和这四个分区.然后重新分配了6个分区,并且使用最后5个分区创建了data5磁盘组.使用了一段时间之后,由于oracle空间不足,检查的时候误以为这个lun就前面15个分区使用,人工把后面的6个分区给删除了,并且创建了4个新分区,然后发现数据库crash了,发现误删除了在使用的分区.然后又把新创建的4个分区给删除了.接手该故障的时候,这个39T lun的分区信息如下
[root@node1 linux64]
|
客户正常使用情况下,这个lun上面相关分区的asm disk信息
SQL>
|
基于客户现在的情况,data4中的所有分区都正常,主要是要找出来data5中的5个分区的数据.因为客户不确定p16分区大小,导致后续的5个分区起始位置不好定位.从而使得恢复无法进行.通过shell脚本结合kfed尝试定位asm disk header信息
#!/bin/bash
|
结果发现无法获取到结果,通过分析发现这里由于lun过大,导致aun值过大,从而使得kfed溢出无法读取到正常值.根据parted的特性,人工dd部分block进行分析
[root@node1 bak]
|
顺利找到了data5中的第一块磁盘,而且确定了起始位置,然后构造相关的dd语句把分区的数据dd到一个新磁盘中
dd
|
然后通过kfed查看数据
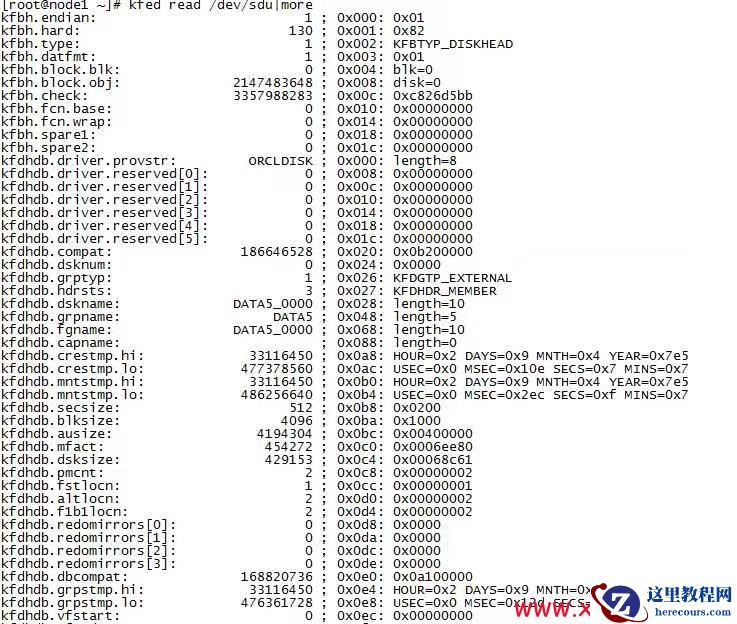
通过类似方法依次处理,最终把5块asm disk全部找到,并且顺利dd到新的磁盘中.尝试启动crs,并mount data5
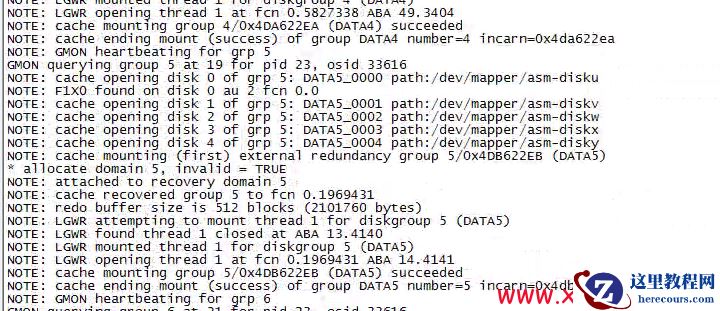
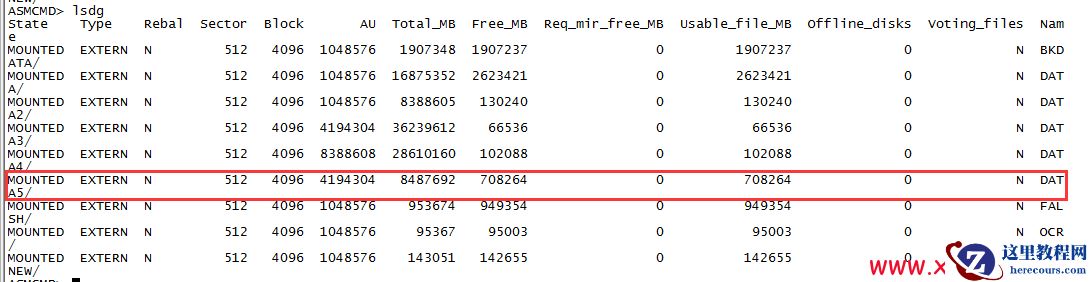
data5 磁盘组mount成功之后,数据库顺利启动,实现lun中删除分区之后,asm磁盘组数据完美恢复
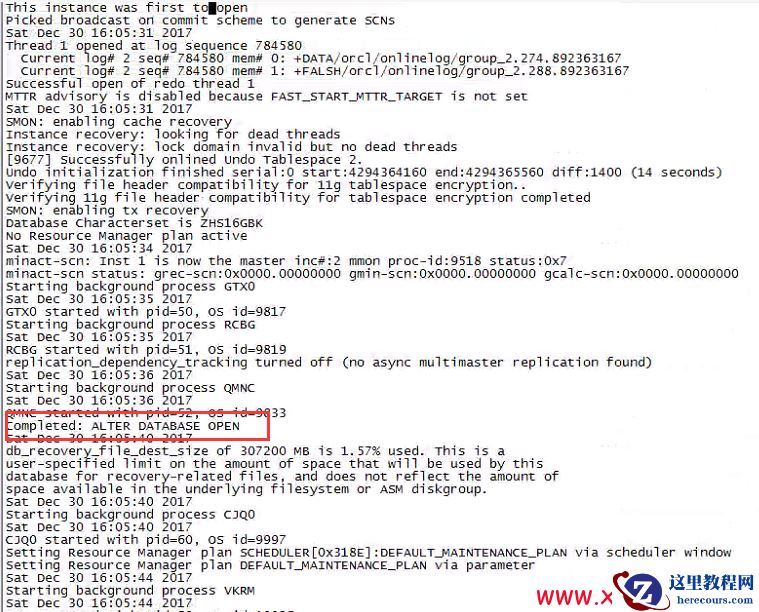
这次运气还不错,仅仅是对lun的分区使用了parted进行了删除和创建等操作,没有格式化文件系统和做成新的asm disk,不然数据会有一部分丢失.对于有部分破坏的分区,需要通过底层碎片的方法进行最大限度抢救数据.参考类似文档: asm disk被加入vg恢复 又一例asm格式化文件系统恢复 文件系统损坏导致数据文件异常恢复 一次完美的asm disk被格式化ntfs恢复 Oracle 数据文件大小为0kb或者文件丢失恢复 再一起asm disk被格式化成ext3文件系统故障恢复 oracle asm disk格式化恢复—格式化为ext4文件系统 oracle asm disk格式化恢复—格式化为ntfs文件系统 分享oracleasm createdisk重新创建asm disk后数据0丢失恢复案例
编辑推荐:
相关推荐
-

-
-
-
-
-
-
-
-
-
-
-
-
-
-

雷神推出 MIX PRO II 迷你主机:基于 Ultra 200H,玻璃上盖 + ARGB 灯效
2 月 9 日消息,雷神 (THUNDEROBOT) 现已宣布推出基于英
-

制造商 Musnap 推出彩色墨水屏电纸书 Ocean C:支持手写笔、第三方安卓应用
2 月 10 日消息,制造商 Musnap 现已在海外推出一款 Oce

热文推荐
- 删除分区 oracle asm disk 恢复

删除分区 oracle asm disk 恢复
26-03-03 - 磁盘空间不足迁移数据文件导致故障恢复

磁盘空间不足迁移数据文件导致故障恢复
26-03-03 - ORACLE dbms_scheduler.create_job创建job作业遭遇PLS-00306
- 文件系统重新分区oracle恢复

文件系统重新分区oracle恢复
26-03-03 - ORA-600 16703故障解析—tab$表被清空

ORA-600 16703故障解析—tab$表被清空
26-03-03 - D77758CN20_sg1_Oracle Database 12c New Feather for DBA
- Oracle_11gR2_概念_中英文对照

Oracle_11gR2_概念_中英文对照
26-03-03 - Oracle 10053跟踪诊断SQL
Oracle 10053跟踪诊断SQL
26-03-03 - Oracle Database 11g RAC手册

Oracle Database 11g RAC手册
26-03-03 - Oracle.Database.12c.Release.2.Real.Application.Clusters.Handbook

