问题描述:XX库节点2的OS hang,命中redhat bug,华为在做了reboot之后,数据库监听资源虽然状态正常(online),但是监听hang,无法对外提供服务,至此应用一直run在节点1上。 1. 问题处理
1.1 背景情况简述
XX库节点 2的O S hang,命中redhat bug,华为在做了reboot之后,数据库监听资源虽然状态正常(online),但是监听hang,无法对外提供服务,至此应用一直run在节点1上。
1.2 故障分析
1.2.1 F ull P icture
故障的 full picture和我们随后做的救援如下:
|
10 : 00 : 00 |
节点 2的O S hang ,华为确认为命中 redhat的bug。 |
|
10 : 07 : 00 |
重启节点 2 , osw显示,网络侧随即出现了 tcpAttemptFails 和 T cp R etrans E rror , 监听 hang。 |
|
23:00:00 |
重启订单库两个节点 os,未解决。尝试收集监听trace,因为监听hang收集失败。 |
|
22:00:00
|
启动节点 2的crs,对1 521 做 tcpdump,发现V IP 和 public IP 上都存在大量的 tcp retransmission ,网络层存在严重问题。手动为节点 2添加1 522 的静态监听,无异常。 另外,观察到监听在启动的过程中并非立马就 hang,会有1- 2 秒的连接成功,之后会有 1 200 个左右的瞬间连接请求,之后监听 hang。 |
|
22:30:00 |
删除 RAC 的 1 521 监听,在两个节点添加 1 521 静态监听,节点 1 ok,节点2还是异常。 配置好 1 522 端口的动态监听,以备不时之需。 删除 oracle句柄文件,重启,未解决。 |
1.2.2 O SW 分析
( 1)网络层
Ø T CP R etrans E rror Ra te
从 OS reboot之后,1 0 点 2 0 开始出现 T CP R etrans E rror,之后监听hang :
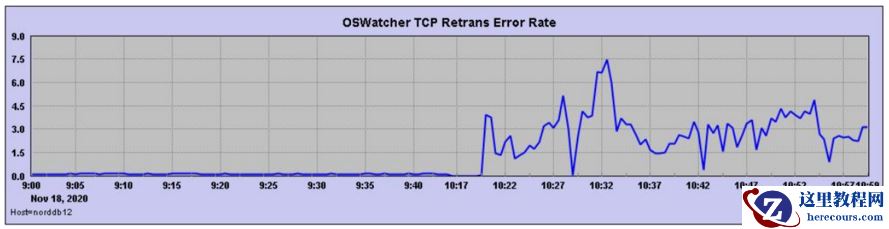
我们把时间拉长,发现重启之后
T
CP R
etrans
E
rror一直存在:
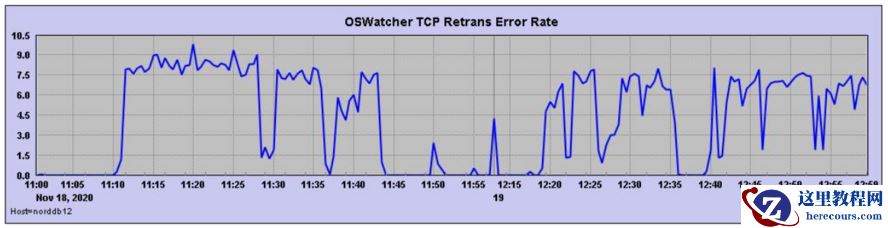
需要 OS 工程师从主机层面、网络层面排查 T CP R etrans E rror原因。
Ø tcpAttemptFails
重启之后也出现了严重的 tcpAttemptFails :
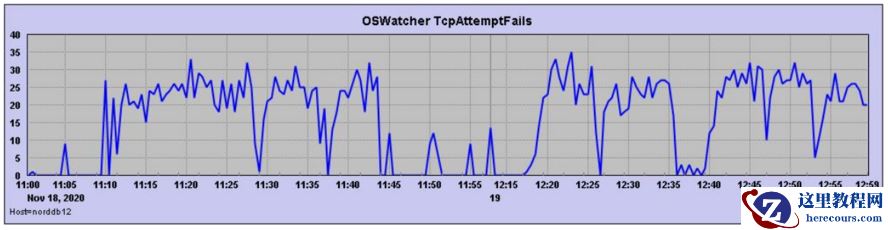
tcpAttemptFails : TCP连接从SYN-SENT状态或SYN-RCVD状态直接转换为CLOSED状态的次数,以及TCP连接已从SYN-RCVD直接转换为LISTEN状态的次数。
当 服务器 收到重置并且我们发送了syn时,或者在发送syn以后连接超时时,tcpAttemptFails 会出现增加 。
TCP state diagram :
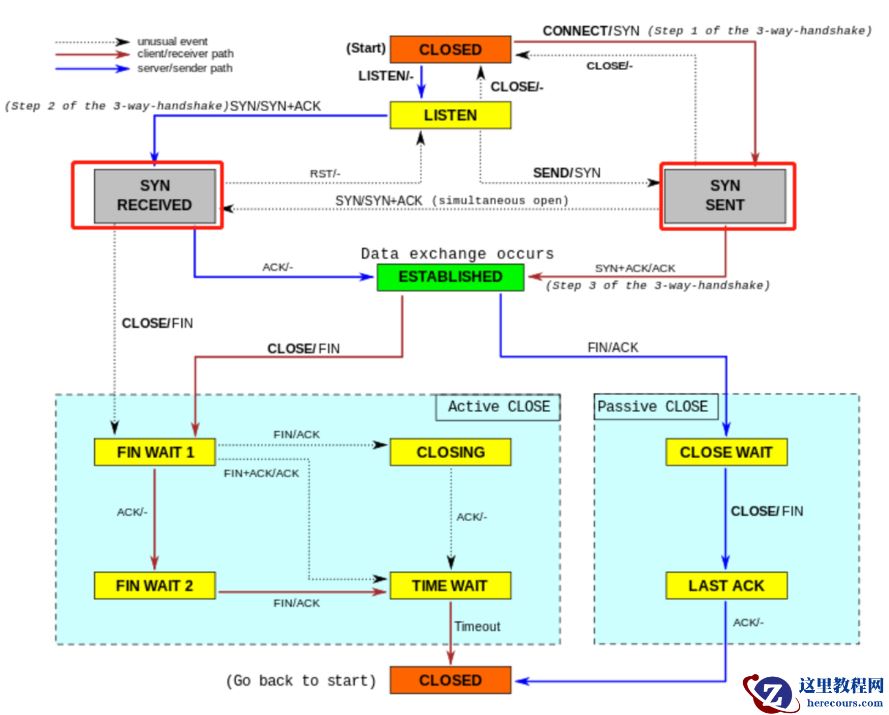
On an incoming connection, it increments if we receive a syn and then send one, but do not get a response, or get a reset .
在 OS 重启之后,就出现了 tcpAttemptFails , 需要网络侧排查失败的原因。
1.2.3 tcpdump分析
(1) 连接测试
tcpdump -i any -s 0 host VIP and port 1521 -v -w netcap.cap
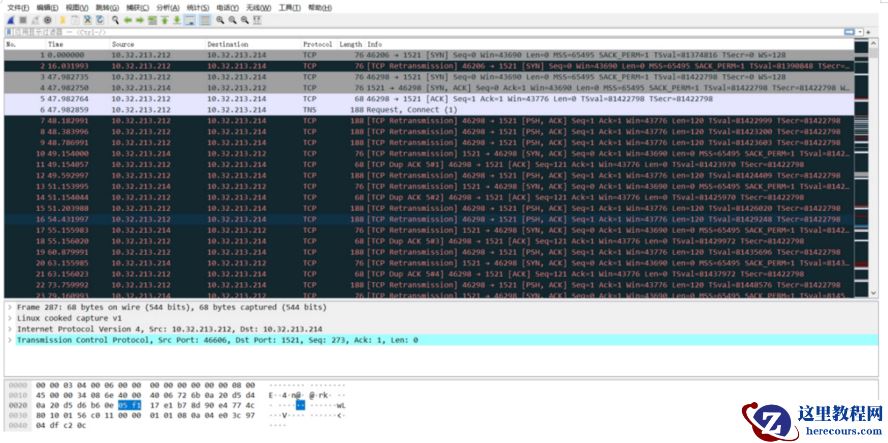
收集并解析之后,发现节点 2的vip和public IP 在 1521等端口上也存在大量的 tcp retransmission ,需要网络侧检查 异常原因 :
<<<<<public ip>>>>
<<<<VIP>>>>
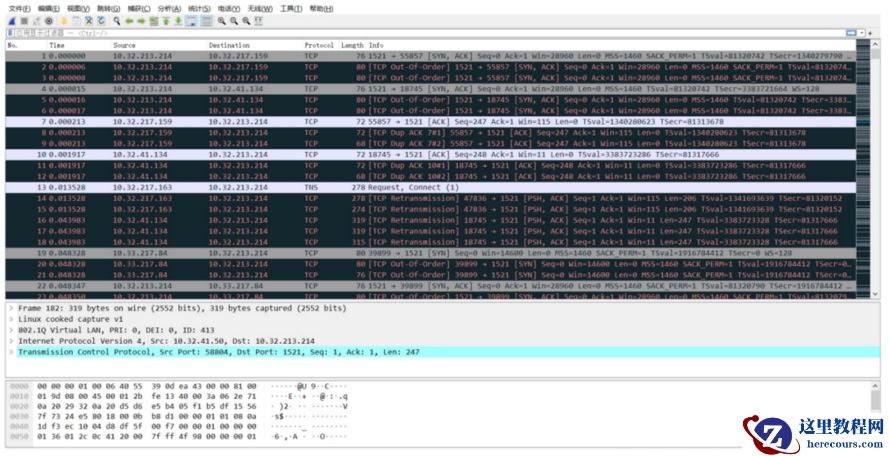
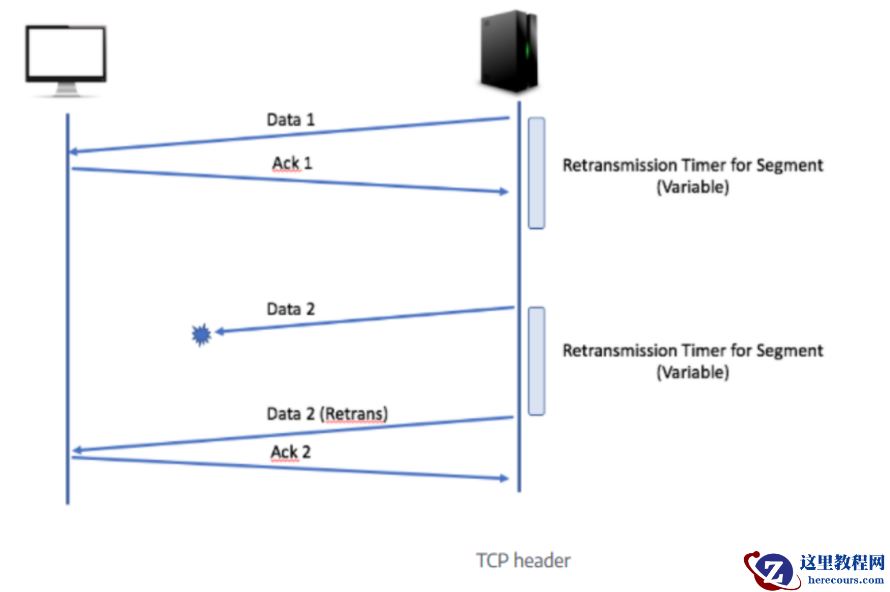
T cp retransmission :
The TCP retransmission mechanism ensures that data is reliably sent from end to end. If retransmissions are detected in a TCP connection, it is logical to assume that packet loss has occurred on the network somewhere between client and server .
1.2.4 监听日志分析
在启动节点
2的同时,不断的tnsping
vip,发现监听在启动初期并非立马hang,会有短暂的1-
2
秒的连接成功:
监听日志中记录了短暂的几个连接成功:
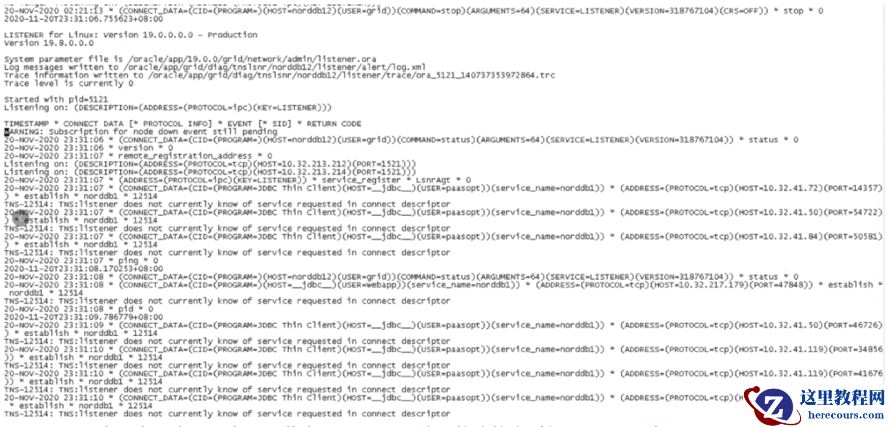
另外,我们也观察到,在
CRS
其中之后,
1
521
端口的连接会瞬间涨到
1
200
左右:
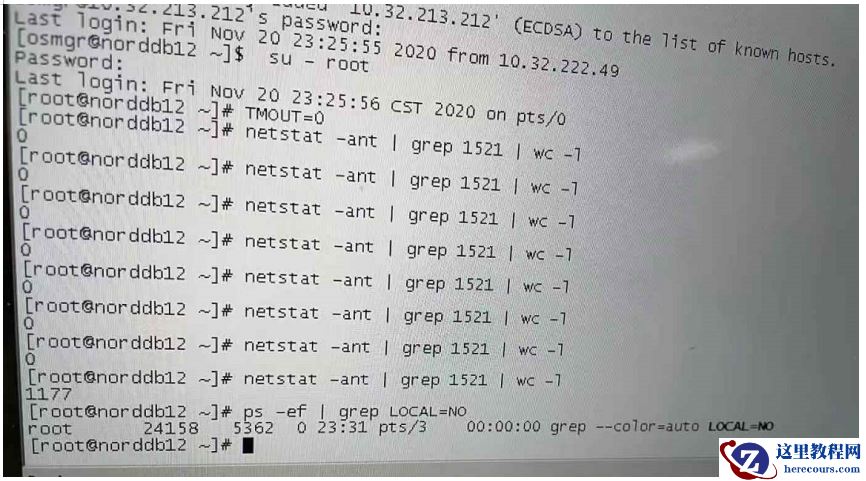
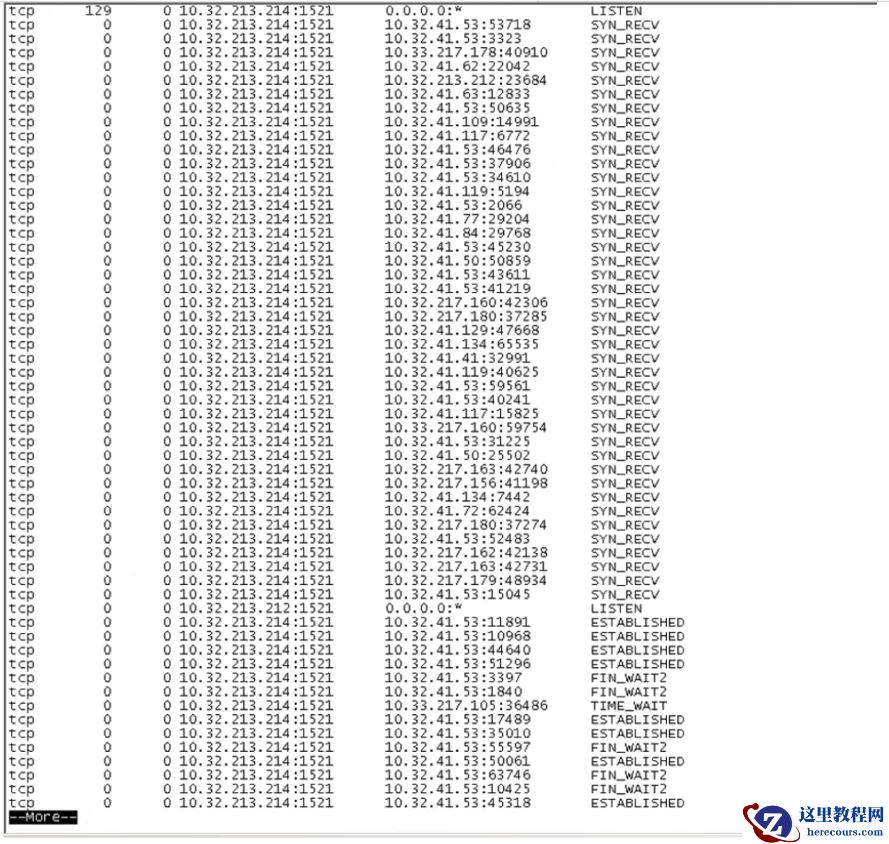
1)上面的netstat输出中都是hang在S YN_RESC 阶段,和 osw中的现象匹配
( 2)我们按照2 .2.6 的步骤创建了 1 522 端口的动态监听,并使用下面脚本对 1 522 端口做登录压测,登入会很快创建,监听无异常:
<<<<<1 tnsping测试
#!/bin/bash
for i in {1..2000}
do
echo $i
nohup tnsping 192.168.56.65 &
done
exit 0
<<<<2 sqlplus 登录测试 (1)connect.sh #!/bin/bash sqlplus -S xiaoyu/xiaoyu@ORCL_NOSET_BALANCE<<EOF select instance_name from v\$instance; EOF
(2)run.sh
#!/bin/bash
for i in {1..2000}
do
nohup connect.sh &
done
exit 0
登录无异常:
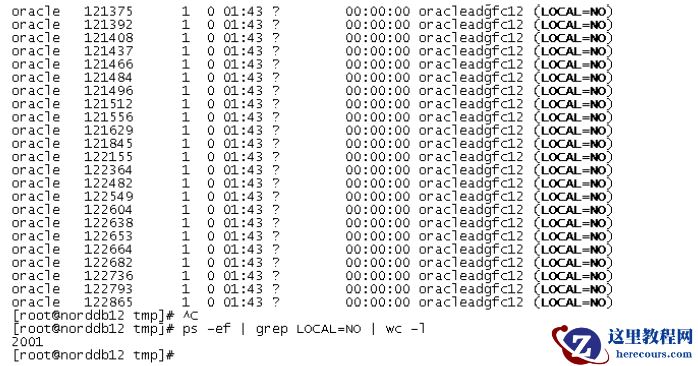
因为我们的压测使用的是在单线程中,通过循环的方式在后台去创建并发连接,创建 2000 个并发连接的时间大概在 1- 2 秒,和实际 web server使用连接池去并发创建连接的方式相比,瞬间建链的快速程度还是有差异的, 所以有可能的话,建议使用 19.32.41.53 ( nestat显示,监听hang之前的连接请求都是该I P 上的应用发起的)上的应用,对 1 522 端口做连接的压力测试。
1.2.5 监听 S trace分析
(1) 测试命令:
strace -frT -o /tmp/strace-lsnr.log -p 79751 <<<其中79751为监听pid
(2) Output:
……
[root@norddb12 ~]# more /tmp/strace-lsnr.log
80000 0.000000 restart_syscall(<... resuming interrupted poll ...> <unfinished ...>
79751 0.000048 epoll_wait(10, <unfinished ...>
80000 1.088555 <... restart_syscall resumed> ) = 0 <1.088558>
80000 0.000042 read(13, 0x7fffe8000950, 2048) = -1 EAGAIN (Resource temporarily unavailable) <0.000017>
80000 0.000072 poll([{fd=13, events=POLLIN}], 1, 5000) = 0 (Timeout) <5.005050>
80000 5.005131 read(13, 0x7fffe8000950, 2048) = -1 EAGAIN (Resource temporarily unavailable) <0.000014>
80000 0.000046 poll([{fd=13, events=POLLIN}], 1, 5000) = 0 (Timeout) <5.005045>
80000 0.007430 poll([{fd=13, events=POLLIN}], 1, 5000) = 0 (Timeout) <5.005058>
80000 5.005128 read(13, 0x7fffe8000950, 2048) = -1 EAGAIN (Resource temporarily unavailable) <0.000015>
80000 0.007015 poll([{fd=13, events=POLLIN}], 1, 5000) = 0 (Timeout) <5.005052>
80000 5.005122 read(13, 0x7fffe8000950, 2048) = -1 EAGAIN (Resource temporarily unavailable) <0.000015>
80000 0.007004 poll([{fd=13, events=POLLIN}], 1, 5000) = 0 (Timeout) <5.005053>
80000 5.005123 read(13, 0x7fffe8000950, 2048) = -1 EAGAIN (Resource temporarily unavailable) <0.000015>
80000 0.007026 poll([{fd=13, events=POLLIN}], 1, 5000) = 0 (Timeout) <5.005051>
80000 5.005123 read(13, 0x7fffe8000950, 2048) = -1 EAGAIN (Resource temporarily unavailable) <0.000018>
80000 0.006933 poll([{fd=13, events=POLLIN}], 1, 5000) = 0 (Timeout) <5.002518>
80000 5.006211 read(13, 0x7fffe8000950, 2048) = -1 EAGAIN (Resource temporarily unavailable) <0.000014>
80000 0.000046 poll([{fd=13, events=POLLIN}], 1, 5000) = 0 (Timeout) <5.002263>
80000 5.002330 read(13, 0x7fffe8000950, 2048) = -1 EAGAIN (Resource temporarily unavailable) <0.000013>
80000 0.000049 poll([{fd=13, events=POLLIN}], 1, 5000) = 0 (Timeout) <5.004880>
80000 5.004951 read(13, 0x7fffe8000950, 2048) = -1 EAGAIN (Resource temporarily unavailable) <0.000016>
80000 0.004987 poll([{fd=13, events=POLLIN}], 1, 5000) = 0 (Timeout) <5.005054>
80000 5.005126 read(13, 0x7fffe8000950, 2048) = -1 EAGAIN (Resource temporarily unavailable) <0.000015>
80000 0.007121 poll([{fd=13, events=POLLIN}], 1, 5000) = 0 (Timeout) <5.004700>
80000 5.004765 read(13, 0x7fffe8000950, 2048) = -1 EAGAIN (Resource temporarily unavailable) <0.000018>
80000 0.007260 poll([{fd=13, events=POLLIN}], 1, 5000 <detached ...>
……
从 strace 来看, 暂时无法看出listener hang的原因:
Ø 主进程没看到动作 。
Ø 子线程一直poll(像是空闲) 。
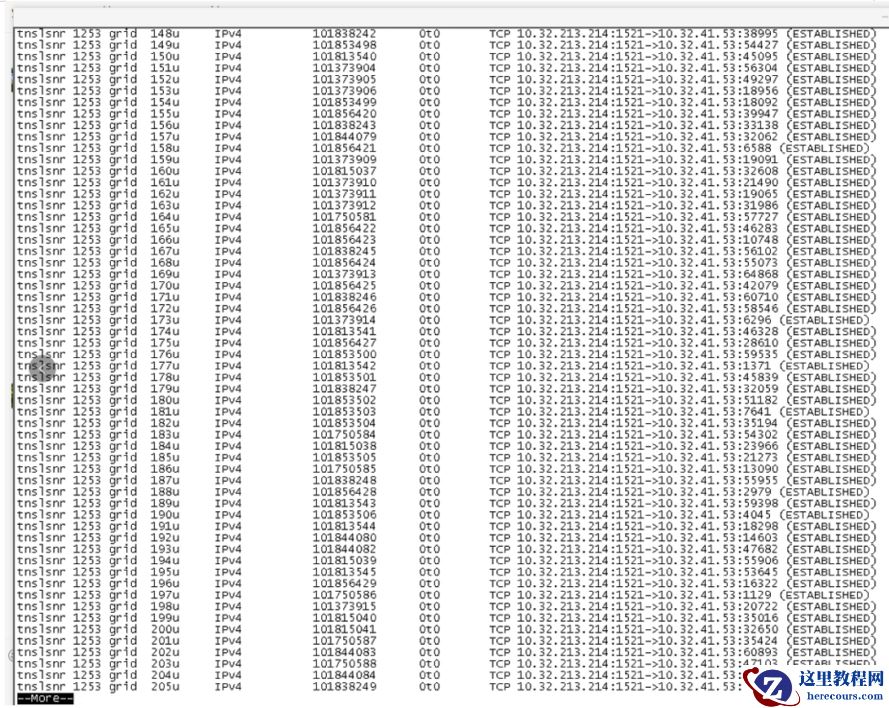
Ø F d= 13 为 I PV6 type,我们对比了一下节点1的 F d= 13 ,未发现异常:
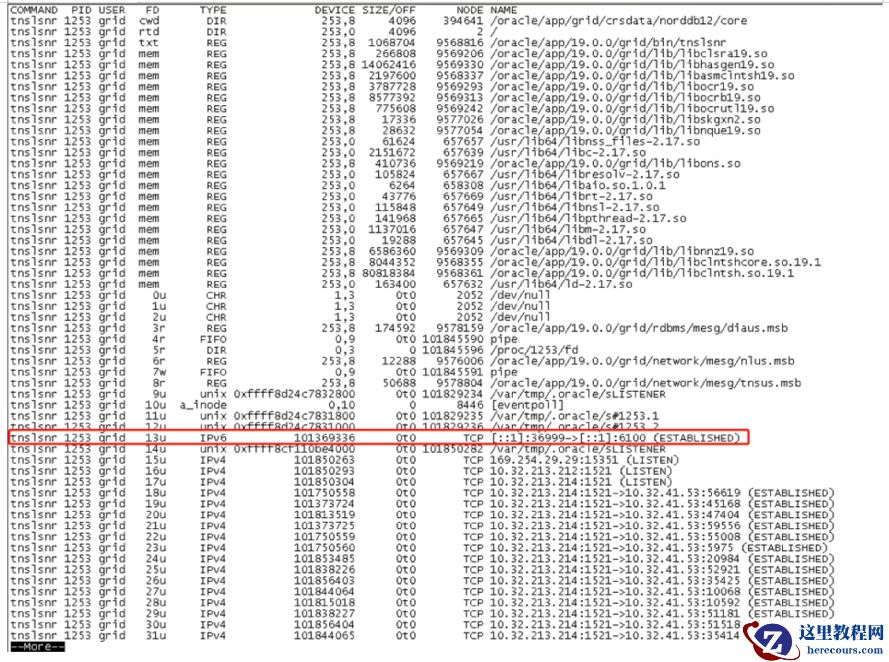
节点 1:

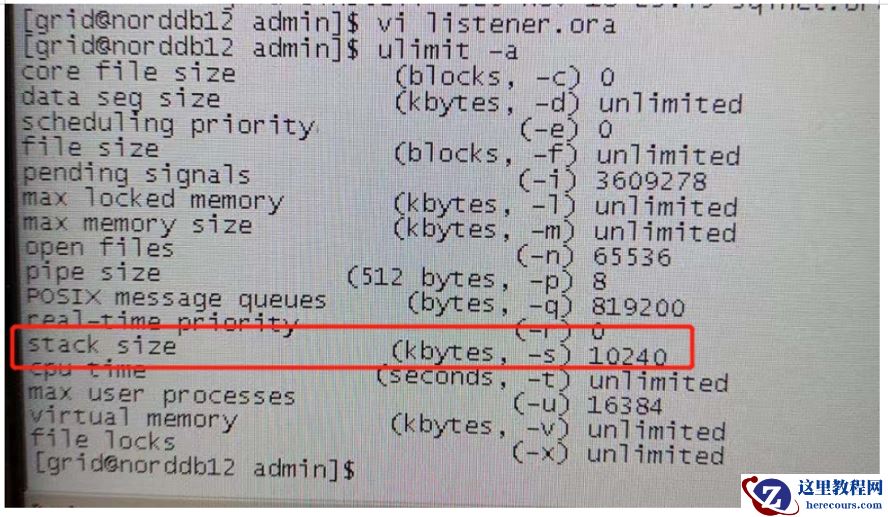
Ø Resource temporarily unavailable:
1)检查/etc/security/limits.conf中,下面参数,正常
oracle soft nproc 16384 oracle hard nproc 16384
2)检查ulimit -a,修改下面值到131072,未解决
1.2.6 1 522 测试
在 1 1 月 1 9 日晚上,测试了将 1 521 对应的监听 做remove 再add , 监听还是hang:
srvctl remove listener -listener listener srvctl add listener -listener LISTENER -endpoints "1521" srvctl start listener -listener listener
测试 1 522 端口的监听,脚本如下:
<<<<<1 tnsping测试
#!/bin/bash
for i in {1..2000}
do
echo $i
nohup tnsping 192.168.56.65 &
done
exit 0
<<<<2 sqlplus 登录测试
(1)connect.sh
#!/bin/bash
sqlplus -S xiaoyu/xiaoyu@ORCL_NOSET_BALANCE<<EOF
select instance_name from v\$instance;
EOF
( 2 ) run.sh
#!/bin/bash
for i in {1..2000}
do
nohup connect.sh &
done
exit 0
另外在 11 月 20 号晚上,我们在节点上配置了 1 522 端口的动态监听: 删除 1521 动态监听,创建 1521 静态监听
srvctl stop listener -listener listener srvctl remove listener -listener listener
修改节点 2 的 grid 的 listener.ora 文件,添加 LISTENER2 port 1521 静态监听测试是否正常
LISTENER2 = (DESCRIPTION_LIST = (DESCRIPTION = (ADDRESS = (PROTOCOL = TCP)(PORT = 1521)) (ADDRESS = (PROTOCOL = IPC)(KEY = EXTPROC1521)) ) ) SID_LIST_LISTENER2 = (SID_LIST = (SID_DESC = (GLOBAL_DBNAME = XORDDB1) (ORACLE_HOME = /oracle/app/oracle/product/19.0.0/db_1) (SID_NAME = adgfc12) ) )
lsnrctl start LISTENER2 测试完毕后 重新添加 LISTENER port 1521 动态监听恢复原样
srvctl add listener -listener LISTENER -endpoints "1521" srvctl start listener -listener LISTENER
1.2.7 删除 oracle句柄文件
删除节点 2的句柄文件,并重启crs,未解决问题:
crsctl stop crs - f rm -rf /tmp/.oracle rm -rf /var/tmp/.oracle rm -rf /usr/tmp/.oracle
1.2.8 MAX_REG_CONNECTIONS_listener
监听日志中 ,在 OS 故障 reboot之后,监听第一次hang出现的报错如下:
…… 2020-11-18T10:46:34.922772+08:00 18-NOV-2020 10:46:34 * (CONNECT_DATA=(CID=(PROGRAM=JDBC Thin Client)(HOST=__jdbc__)(USER=paasopt))(service_name=omsdb)) * (ADDRESS=(PROTOCOL=tcp)(HOST=10.32.41.129)(PORT=19596)) * establish * omsdb * 12518 TNS-12518: TNS:listener could not hand off client connection TNS-12540: TNS:internal limit restriction exceeded 2020-11-18T10:46:36.828479+08:00 18-NOV-2020 10:46:36 * (CONNECT_DATA=(CID=(PROGRAM=JDBC Thin Client)(HOST=__jdbc__)(USER=paasopt))(service_name=norddb1)) * (ADDRESS=(PROTOCOL=tcp)(HOST=10.32.41.84)(PORT=24604)) * establish * norddb1 * 12514 TNS-12514: TNS:listener does not currently know of service requested in connect descriptor 2020-11-18T10:46:50.839951+08:00 18-NOV-2020 10:46:50 * service_update * corddb12 * 0 2020-11-18T10:47:29.874059+08:00 18-NOV-2020 10:47:29 * service_update * corddb12 * 0 2020-11-18T10:47:32.878633+08:00 18-NOV-2020 10:47:32 * service_update * corddb12 * 0 2020-11-18T10:48:35.934738+08:00 18-NOV-2020 10:48:35 * service_update * corddb12 * 0 2020-11-18T10:50:24.036527+08:00 18-NOV-2020 10:50:24 * service_update * corddb12 * 0 2020-11-18T10:51:09.077662+08:00 18-NOV-2020 10:51:09 * service_update * corddb12 * 0 2020-11-18T10:55:20.527607+08:00 No longer listening on: (DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=10.32.213.212)(PORT=1521))) 2020-11-18T10:55:23.934324+08:00 ……
根据我们的经验, Internal connection limit 可以认为是 Oracle Net Listener 可支持的最大并发注册连接会话数。需要增大 MAX_REG_CONNECTIONS_listener_name 参数,当前值为默认的 128 。
修改 listener.ora,添加监听参数 MAX_REG_CONNECTIONS_listener =2048 ,重启监听,未解决。
1.2.9 S R 后线分析
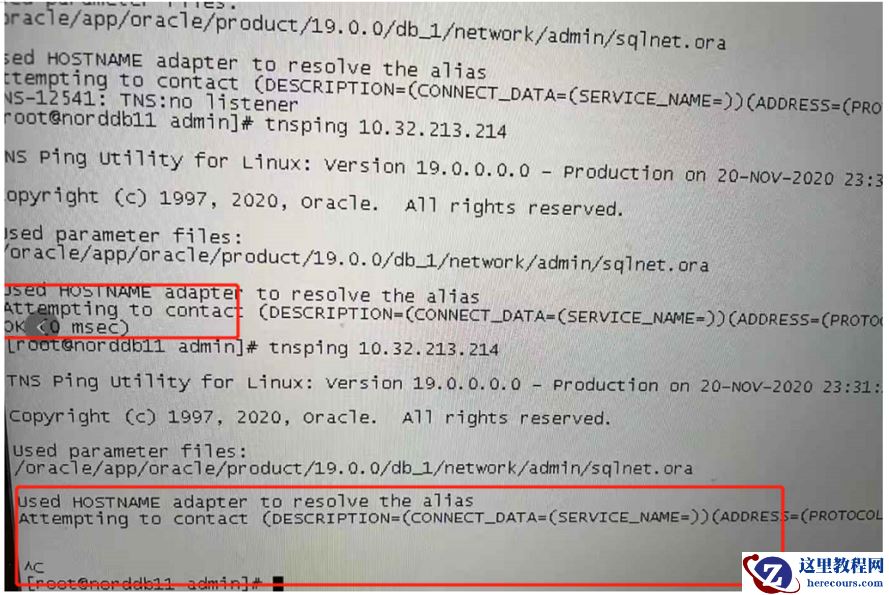
目前
oracle后线也认为该问题和网络、
OS
有关:

2.1 建议
总结:
u 从 osw来看,os 重启之后, 网络上 存在严重的 TCP Retrans Error Rate、tcpAttemptFails 等; tcpdump也显示节点2的 VIP 和 public IP 在 1521端口上也存在严重的 tcp retransmission 。
u 从 osw和tcpdump来看有些连接是 OS层没有回复建立连接(syn_recv),有些是TNS层问题
建议:
u 建议 OS厂商分析网络上的TCP Retrans Error Rate、tcpAttemptFails
u 建议使用 19.32.41.53上的应用,对1522端口做连接的压力测试, 测试和 评估1200个瞬间 连接给监听代来的影响。







")


