查询条件超过一个月就不走索引:
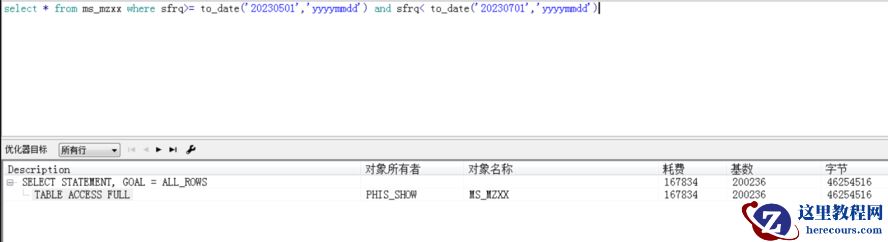
检查表的block数和数据行数:
select blocks,num_rows from dba_tables where table_name='MS_MZXX'; blocks:618687 num_rows:20335462
查看聚簇因子clustering_factor的数: select clustering_factor from dba_indexes where index_name='IDX_MS_MZXX_SFRQ'; clustering_factor:18031075
设置聚簇因子clustering_factor大小为500万:
exec dbms_stats.set_index_stats(ownname => 'PHIS_SHOW',indname => 'IDX_MS_MZXX_SFRQ',clstfct => 5000000);
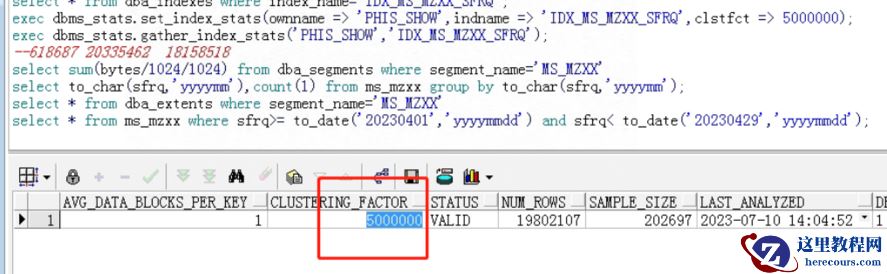
设置成500万后,查询终于走索引。
Clustering Factor的计算方式如下: 扫描一个索引(large index range scan),比较某行的rowid和前一行的rowid,如果这两个rowid不属于同一个数据块,那么cluster factor增加1;整个索引扫描完毕后,就得到了该索的clustering_factor。
按照这个计算,clustering_factor应该比块数稍微大一些。差异特别大,可以对索引做rebuild操作,聚簇因子会自己改成合适的数值,略大于块数。
正常情况blocks<clustering_factor<num_rows,clustering_factor越靠近block数,说明表中的记录很有序,读取少量的data block就能得到想要的数据,但clustering factor接近表记录数,说明表的存储和索引排序差异很大,在做index range scan的时候,会额外读取多个block,代价较高。
编辑推荐:
- 索引聚簇因子clustering_factor太大导致不走索引03-03
- oracle数据库如何正确建主键03-03
- 升级到oracle 19.8后vm_concat函数不可用怎么解决03-03
- Oracle RAC 修改SCANIP地址03-03
- 表达式统计信息收集03-03
- 跨境电商“卷向”海外03-03
- 数据库管理-第155期 记一次发生在备库上的故障处理(20240226)03-03
- oracle数据库高水位征用问题及解决办法03-03
相关推荐
-

-
-
-
-
-
-
-
-
-
-
-
-
-
-

雷神推出 MIX PRO II 迷你主机:基于 Ultra 200H,玻璃上盖 + ARGB 灯效
2 月 9 日消息,雷神 (THUNDEROBOT) 现已宣布推出基于英
-

制造商 Musnap 推出彩色墨水屏电纸书 Ocean C:支持手写笔、第三方安卓应用
2 月 10 日消息,制造商 Musnap 现已在海外推出一款 Oce
热文推荐
- 索引聚簇因子clustering_factor太大导致不走索引

索引聚簇因子clustering_factor太大导致不走索引
26-03-03 - 升级到oracle 19.8后vm_concat函数不可用怎么解决

升级到oracle 19.8后vm_concat函数不可用怎么解决
26-03-03 - 跨境电商“卷向”海外
跨境电商“卷向”海外
26-03-03 - 数据库管理-第155期 记一次发生在备库上的故障处理(20240226)
")
数据库管理-第155期 记一次发生在备库上的故障处理(20240226)
26-03-03 - oracle数据库高水位征用问题及解决办法

oracle数据库高水位征用问题及解决办法
26-03-03 - 数据库专用、共享服务连接报ORA-12520

数据库专用、共享服务连接报ORA-12520
26-03-03 - oracle XTTS迁移问题整理
oracle XTTS迁移问题整理
26-03-03 - 数据库管理-第151期 Oracle Vector DB & AI-03(20240218)
- LGWR写操作会导致性能全局卡顿案例分析

LGWR写操作会导致性能全局卡顿案例分析
26-03-03 - 手机玩家“战”AI,OPPO向左,魅族向右
手机玩家“战”AI,OPPO向左,魅族向右
26-03-03
")