故障描述
2024 年 4 月 24 日,客户反馈,多个 oracle 数据库多次出现 process 爆满的问题,涉及 windows 和 linux 的。导致业务无法连接的问题,当前处理方式,尝试把非 sys 进程全部杀掉,但是过段时间 process 还是爆满。 现场同事已经和客户进行沟通,并登陆过数据库进行初步检查,反馈 process 和 session 连接数对应不起来,大部分都无法通过连接字段进行关联。如某套库 session 只有 30 多个,但是 process 达到 1000 多个。
问题分析
1. 整体情况
登陆其中一台
windows
数据库
,
检查了数据库连接相关信息。
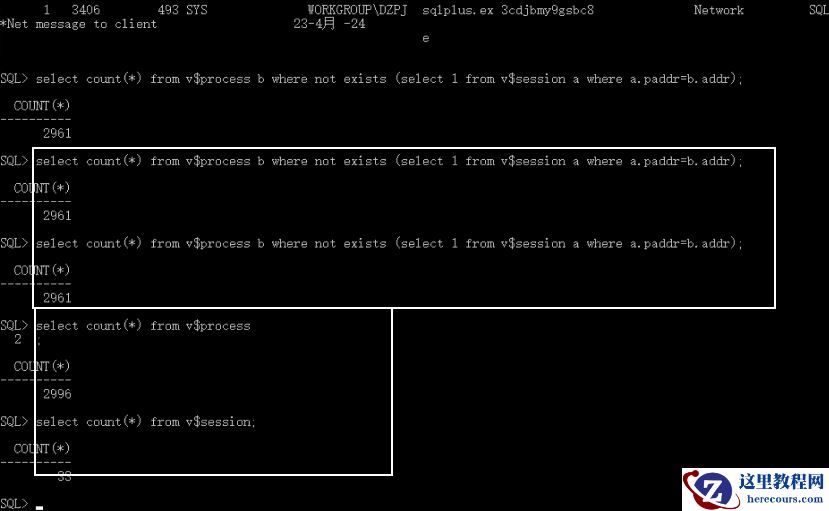
v$session
有
33
个会话,
v$process
有
2996
个连接。竟然有
2961
个
process
和
sesssion
对应不起来的。
看到这里我的第一反应是在杀 session 会话的时候,只是释放了 session ,但是 process 连接没正常释放,以前也碰到过的类似问题,正常 v$session.paddr=v$process.addr 能将两者关联起来,但是有时候没正常释放,就会导致找不到对应的一方,怀疑是查杀的姿势有问题,建议不要通过 alter session 去查杀,直接通过操作系统层面 kill -9 去杀进程。但是同事反馈了客户之前 process 满的时候有手动 kill 过,后面还是会出现满的情况。
另外看了下后台日志,没有跟连接数有关的报错。但是看到一点日志小问题,本次不做重点。

2. 并发问题
同事还反馈了某台
linux
数据库机器上,查看进程发现有很多
p
开头的进程。

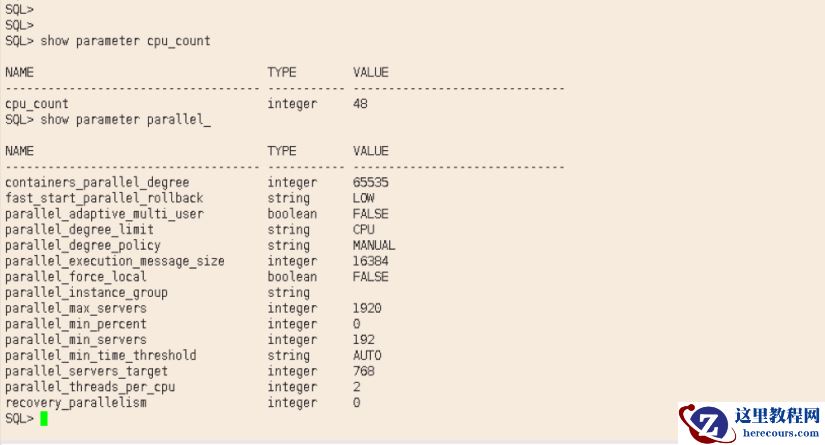
这个是并发衍生的子进程,那么是不是并发开太多了。检查了下参数,
parallel_max_servers
确实有点大,可以到
1920
个,这个是可以同时发起的最大并发进程数。建议调小一点,也可以避免并发猛涨,导致连接数不够的问题。
但是想看下这些并发在做什么?发现因为 session 里面没有对应的会话,所以根本没法看到包含具体语句等更多有用的信息,因为临时通过降低了并发数和增加了 process 参数,客户也 KILL 过进程,信息不多,就建议观察下运行情况。
......( 过了几天 )
3. 调整后,数据库运行情况观察
询问了下情况,说最近没有出现连接数满情况,然后让检查下连接数情况,发现问题还在,只是增长没那么快。情况如下:
l A 库 34 个 session 763 的 process 找不到 session 的 process 有 729 个
l B 库 842 个 session 1170 个 process 找不到session 的 process 有 314 个
l C 库 617 session 1087process 找不到session 的 process 有 483 个 ora_p* 有 230 多个 。
另外客户反馈了一个问题:之前分析的那套 windows 上的数据库 出现了2 次 process 爆满的问题,反馈说以前是不会出现这个问题的,自从用了备份软件后,已经出现 2 次了 。
与备份厂家确认 备份是调用rman 的, 很多客户都用的是相同的版本,未反馈有这样的问题,所以 不会 应该 出现大批量的process 问题 。好吧,那我们就找证据吧。
4. 数据库 BUG
怀疑是不是客户环境有问题,咨询了客户,最近没有其他变动,变动的只有安装了备份软件以后出问题。那是不是数据库 BUG ?但是发现涉及的数据库有 11G , 12C , 19C ,而且 OS 版本有 WINDOWS 和 LINUX 。所以基本上不会是 BUG 问题,排除了。
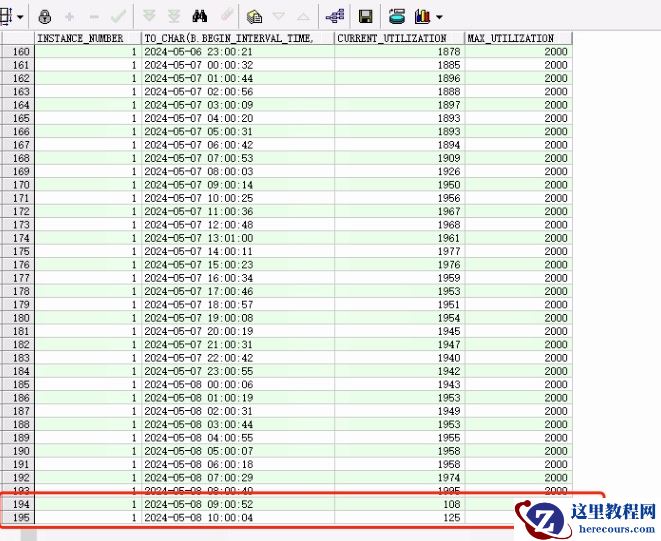
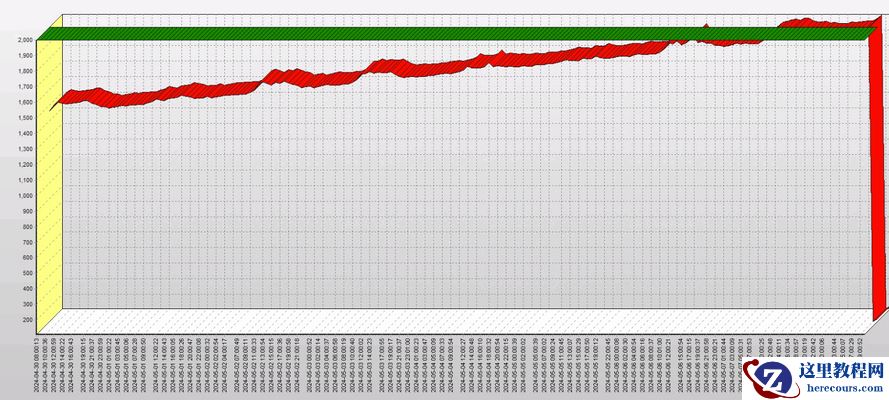
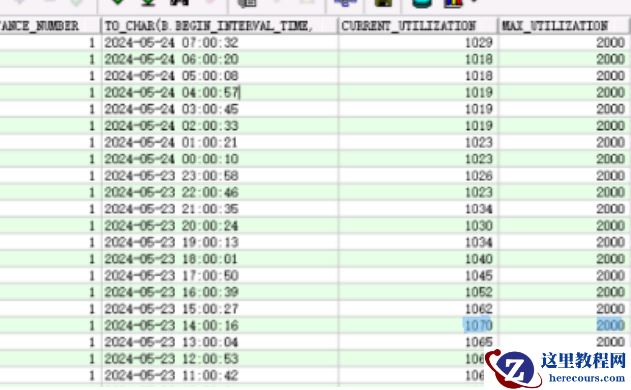
5. 连接数增长趋势
分析近 2 天的 process 连接数历史情况,看到 process 数,并不是暴涨,而是缓慢增长,达到最大值 2000 ,而 2000 也是 process 参数当时设置的限制。
红框是
process
满了后,把进程杀了下降了。
然后做个图,连接数增长趋势更明显。
6. 共享模式
重新整理了下思路,这种场景跟我们平常大部分出现的都是 v$session 满不同,如果是 v$session 过多查询方式很简单,里面有很多的字段可以分析问题,通常是通过下面这台语句就可以看出主要异常程序连接信息。
select username,machine,program,count(*) from v$session where type<>'BACKGROUND' group by username,machine,program ;
但是这次显然不是 session 的问题,就没几个 session ,是 process 的问题,再去分析 v$session 已经没意义了。所以可以通过检查 v$process 表来获取一些信息来,看看是否能发现问题。
在那台
WINDOWS
数据库上执行了
select username,program,count(*) from v$
process
group by username,program
可以看到除了后台进程,都是一个叫
ORACLE.EXE(SHAD)
进程。
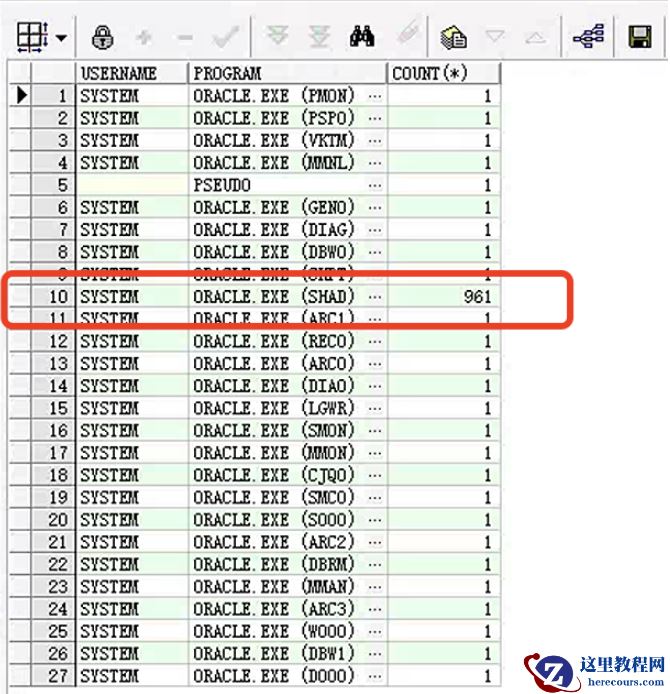
SHAD 咋一看好像是共享( shared )的缩写,感觉是数据库是共享服务器模式,以为找到问题了,于是一通查后,失望,发现客户数据库并非共享模式。
7. rman.exe
别忘了, v$porcess 里面还有一列 tracefile, 这个 trace 里面应该是可以看到很多东西吧。查看 WINDOWS 数据库,确实能看到这些 SHAD 进程用户是 system 的,然后对应都有 tracefile ,这里面应该有些信息可以发现。
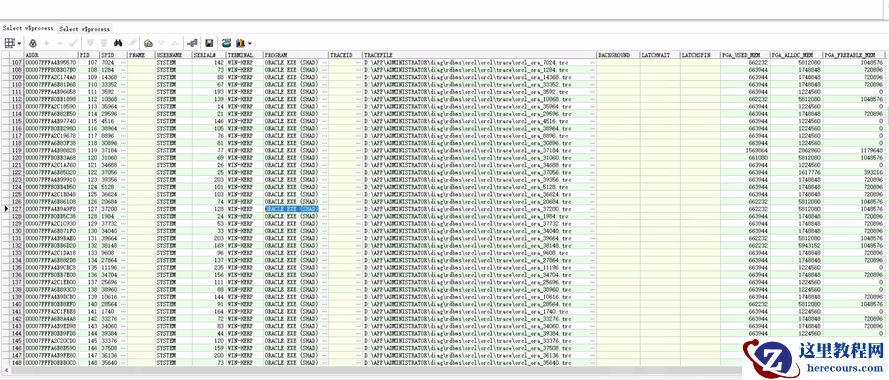 到目录下去找,发现找了好多个
ORACLE.EXE(SHAD)
对应的
trace
文件,发现
trace
文件都不存在了。
到目录下去找,发现找了好多个
ORACLE.EXE(SHAD)
对应的
trace
文件,发现
trace
文件都不存在了。
另外到有问题的 LINUX 数据库服务器上找这些 trace 文件,大部分也都是不存在的。
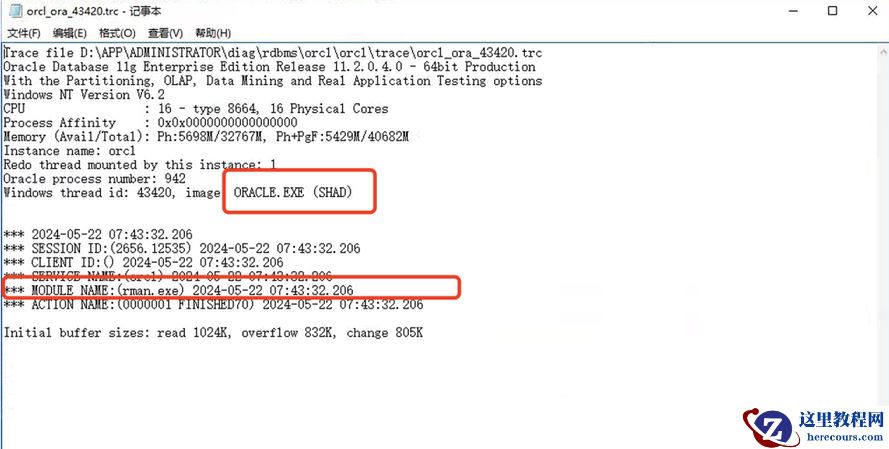
于是在目录下,随便点了一个 trace ,竟然看到了方向了,发现也是 ORACEL.EXE(SHAD ) 这类进程,然后 MODULE NAME( 好可惜 v$process 视图里面不记录这列信息 ) 是 rman.exe, 然后多验证了几个 trace 文件,都是一样指向 rman.exe. 这下真相了,终于找到问题了。
和备份厂家商量,把备份停掉 1 天,验证情况。
...... (第二天早上)
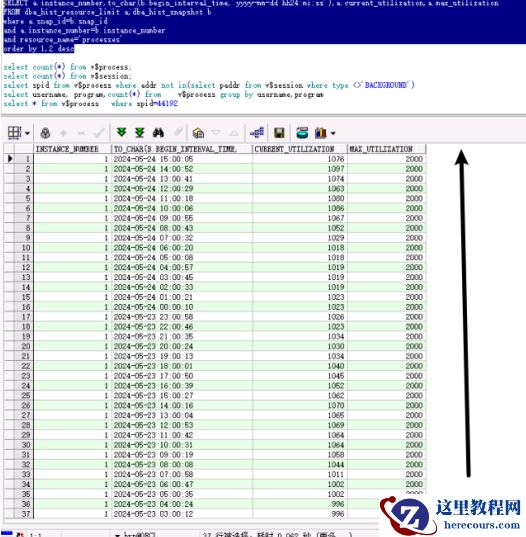
确实可以看到从下午 2 点以后把备份停掉后,连接数从 1070 慢慢下降到 1018 个,这又让我更确定了一点是备份问题,然后客户说要打开了,我建议观察久一点,至少 1 天,于是到让开到下午。
......( 经过了一个早上 )
到了下午再次检查连接数,从早上开始到下午这段时间,连接数又慢慢增加了,差点没吐血啊,竟然不是备份的问题!只能先开启备份,继续找问题。
8. 测试机
因为 ORACEL.EXE(SHAD ) 这类进程,对应的 MODULE NAME 是 rman.exe 这点是不容质疑的,所以我们还是坚持这个方向,于是客户同意部署一套测试数据库,然后没有其他业务连接,只用是打开了备份作业。
......( 等数据 ) ,其他方向并行排查。
事实证明,这个动作对将来证明问题是有积极证据的。
9. 本地作业
通过 crontab -l 看看是不是本地有部署一些 RMAN 作业,配置错误。发现只有一个归档删除脚本,非常的简单,并不需要密码连接。
10. 用户密码错误连接
这个方向其实一开始机有猜测,然后也做了一些实验,通过客户端使用一个错误密码访问另外一台机器上的数据库。查看 v$process 里面都会建立一个连接,但是 v$session 是没有创建会话的,这个可以理解,因为验证没通过。所以猜测是不是应用或者哪个非应用的程序配置了错误密码,导致这个问题,怀疑要么是程序里配置密码错误,要么就是开始配置正确,后面数据库改了密码,但是没有证据啊,连源头谁发起的都没找到,更看不到这个配置了。尝试问了下客户最近有没有改过密码,得到了否定的答案。
如果找不到问题源头,那么是不是可以看看怎么把这些异常连接自动处理掉。也是一种解决方案吧。
数据库有一个配置参数, SQLNET.INBOUND_CONNECT_TIMEOUT , 参数默认是 60 单位是秒,这个参数是对密码验证的一个时间限制,也就是如果是连接密码错误,虽然会建立一个 process, 但是数据库会在 60 秒后对这个 process 连接进行清理 .
查看了这台数据库 SQLNET.ORA 文件中已经设置了这个参数,而且是 1 秒,应该立马会清理,但是目前看起来,连接不断在涨,所以暂时排除是密码错误这个方向吧。
11. TCP连接
每个数据库操作系统外部进程,正常都是会建立 TCP 连接,这样就可以看到本地和对端的 IP ,然后再加上对端 IP 相同条数和数据库里面 proces 条数大致比对下,如果能对上,那么就知道哪台机器连过来的。这样至少是可以知道哪台机器连过来的,于是找了数据库出问题的那台 WINDOWS 服务器查看 TCP 连接。
按 ”远程地址“排了下序,拖了下进度条,可以看到大量的相同 IP ,应该就是这个 IP 了。但是发现本地地址和远程地址都是本机,看来不是其他地方连过来的。但是另外有个发现就是“名称”都是 daclient.exe ,这是啥?问了现场运维的同事感觉有点熟悉,但是想不起来。

然后搜索了下这个文件,确实可以找到这个,同事看了,恍然大悟,这个就是备份的客户端!
这时运维同事补充说,那台只部署了备份的测试库观察下来,连接数也是不断的涨,还是跟备份有关。看来我们坚持的方向是对的。
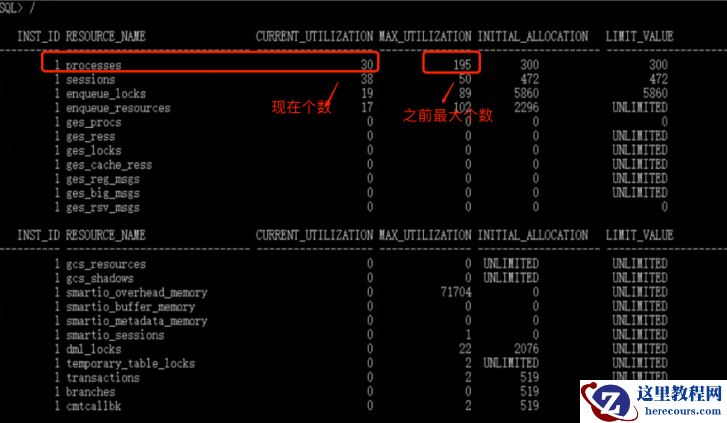
于是让同事在那套测试库所在 WINDOWS 的任务管理器里面,把这个运行程序关了,果然 process 的个数从接近 200 多个下降 30 多个,实锤了!
这也可以解释为什么之前备份服务器上备份作业关掉后,连接数还在涨,因为这个备份客户端还在运行,客户端不断有新连接请求,他们之间没有严格的关闭关系。但是至于为什么客户端连接了数据库后, session 释放了, process 没有释放,需要备份厂家去分析原因。
问题处理
知道了是这个备份客户端导致的问题后,已经问题反馈给厂家,具体原因需要厂家去查。因为备份还是比较重要,所以一方面推进厂家分析原因解决问题。另外一方面定期检查连接情况,提前对过多无效 PROCESS 进行手工提前清理,避免出现 process 满对业务造成影响。
技术原理
1、 process和session的关系
l process是操作系统上创建的连接,连接具体情况可以在v$process视图里面看到.
l session是连接验证通过后,在数据库里面创建起来的会话.
l 他们是通过进行关联 v$process.paddr=v$session.addr,并不全是1:1对应,也可以是1:N,比如一个连接,发起了并发查询。
2、 连接验证
l SQLNET.INBOUND_CONNECT_TIMEOUT ,表示等待用户连接请求超时的时间,参数默认是60单位是秒。如果通过错误密码访问,会在这个参数指定的时间内断开这个连接。
l 如果 SQLNET.ORA这个文件里面没有配置这个参数,那么默认是60秒后,进行清理验证不通过的连接,为了防止恶意攻击,建议这个参数可以设置的比较短,比如1秒。
3、 TCP连接
l WINDOWS可以通过”资源监视器“来查看所有建立起来的TCP连接,查看源端IP和目标端IP。
l LINUX可以通过 lsof -n -P -i tcp 和 netstat -anpt 这两个命令来查看所有建立的TCP连接情况。
建议总结
1. 对于问题处理,建议回顾下问题出现前,做了什么变更,这个可以为问题分析,提供方向。
2. 对于 process 数量远远大于 session 数据的问题处理:短时间内问题无法定位到问题或者无法解决,那么临时通过 OS 命令查杀 process ,设置相对安全的 process 参数后,再加上 process 连接数监控。
3. 对于 process 数量远远大于 session 数据的问题分析:说明已经无法从 v$session 中得到有用的客户端进程信息, v$process 基本上也无法得到有用信息,视图中显示的 trace 文件大多都已经找不到的,所以可以通过 TCP 连接来发现对应客户端 IP 地址和进程。
4. SQLNET.INBOUND_CONNECT_TIMEOUT ,默认是60S,如果使用错误的用户名和密码进行登录,因为需要60S才断开连接,清理进程,如果出现恶意攻击,process连接数将会被瞬间打满。所以有安全要求的客户,可以人为设置一个较低值。









