故障描述
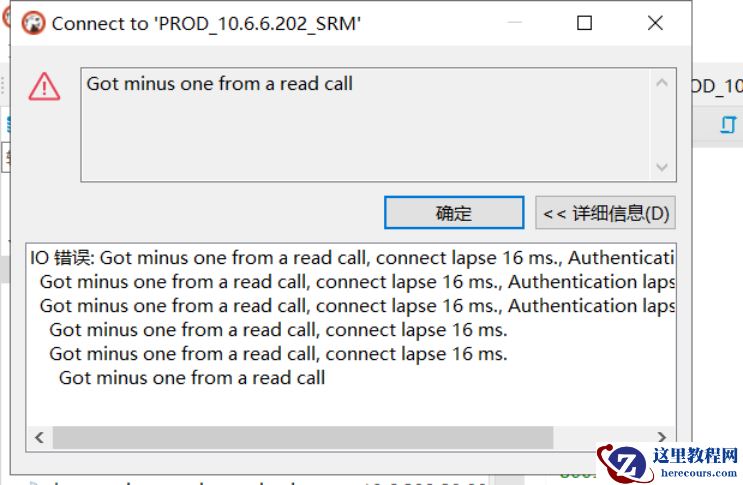
2 024 年 10 月 10 号 11 : 00 左右 ,应用人员 反馈数据库异常 , 连不上数据库 ,报错如下。
原因分析
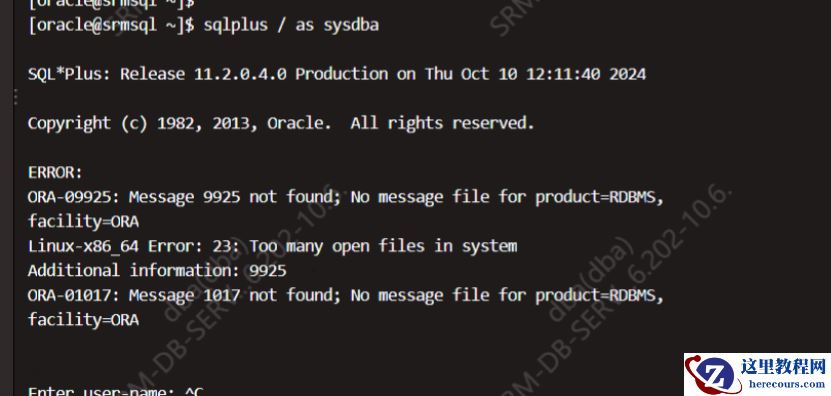
检查 alert 日志,无法打开日志:

从服务无法正常登录数据库
,通过
prelim
方式也登录不了数据库:
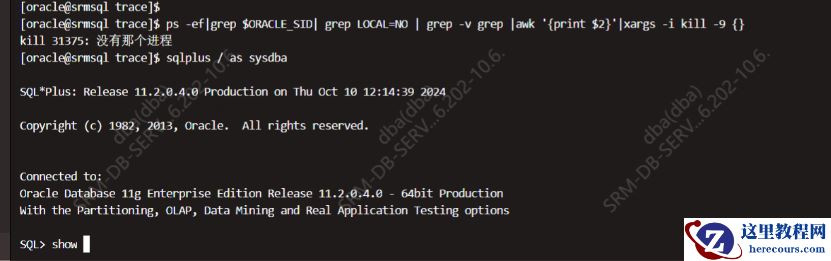
杀掉业务会话
,
登录数据库
:
检查 alert 日志: Thu Oct 10 10:50:28 2024 Process startup failed, error stack: Errors in file /app/oracle/diag/rdbms/srm/srm/trace/srm_psp0_7628.trc: ORA-27300: OS system dependent operation:fork failed with status: 2 ORA-27301: OS failure message: No such file or directory ORA-27302: failure occurred at: skgpspawn5 Process m000 died, see its trace file : 这个报错的原因是服务器open files 参数配置的资源不够导致的 。
检查/etc/security/limits.conf 文件相关的配置 , 没有问题 。
检查oracle
用户环境参数配置
;
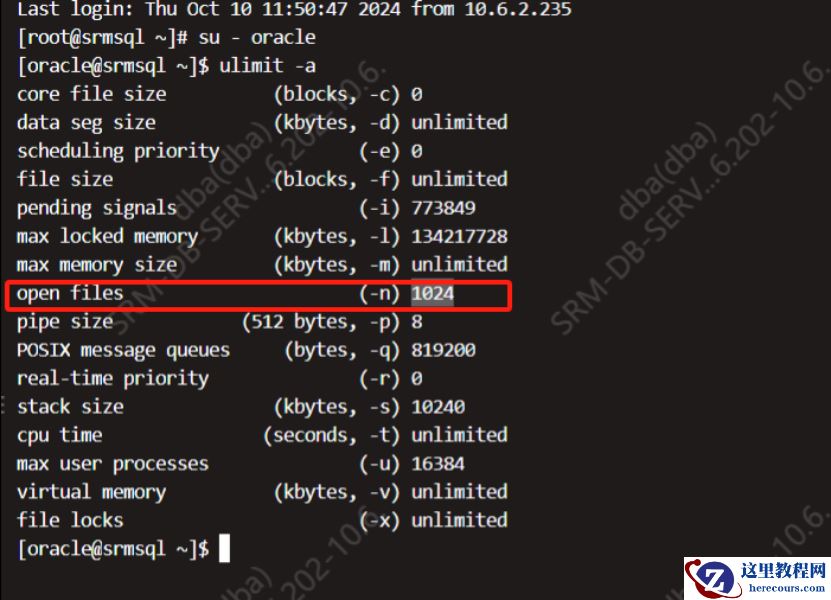 发现open files
才
1
024
,
这个参数明显过低
。
发现open files
才
1
024
,
这个参数明显过低
。
编辑 / etc/profile 配置文件 , 添加参数 : if [ $USER = "oracle" ]; then if [ $SHELL = "/bin/ksh" ]; then ulimit -p 16384 ulimit -n 65536 else ulimit -u 16384 -n 65536 fi umask 022 fi
重启数据库 ,问题临时解决。
检查操作系统日志 : Oct 10 08:19:01 srmsql kernel: device eth0 entered promiscuous mode Oct 10 10:50:20 srmsql kernel: oracle[29625]: segfault at 7fff5ee53828 ip 0000000004b6b171 sp 00007fff5ee53830 error 6 in oracle[400000+b8d4000] Oct 10 10:50:21 srmsql abrt[29630]: Saved core dump of pid 29625 (/app/oracle/product/11.2.0/dbhome_1/bin/oracle) to /var/spool/abrt/ccpp-2024-10-10-10:50:20-29625 (15962112 bytes) Oct 10 10:50:21 srmsql abrtd: Directory 'ccpp-2024-10-10-10:50:20-29625' creation detected Oct 10 10:50:21 srmsql kernel: VFS: file-max limit 6815744 reached Oct 10 10:50:21 srmsql abrtd: Executable '/app/oracle/product/11.2.0/dbhome_1/bin/oracle' doesn't belong to any package and ProcessUnpackaged is set to 'no' Oct 10 10:50:21 srmsql abrtd: 'post-create' on '/var/spool/abrt/ccpp-2024-10-10-10:50:20-29625' exited with 1
检查 / etc/sysctl.conf 配置文件 :
fs.file-max = 6815744
操作系统报错的和配置文件两边的数值是一致的 ,很明显,根据报错信息来看 file-max 参数值不够 。 6815744 这个数值按照 oracle 最佳实践是足够的 , 可以推断肯定是有其他原因导致这个数量增加导致的 。
事后检查进程打开的文件描述符:
检查发现 7903 这个进程打开 8951 个文件描述符 , 也就是打开这么多个文件 ,多个数据库进程打开的文件数量基本一样,而且打开的文件都位于 / dev/shm 目录 。
ls -l /dev/shm |wc -l
8950
如果只检查 /dev/shm 下同进程统计
lsof -n | grep /dev/shm|awk '{print $2}'|uniq -c 会发现大部分进程打开文件数结果确实是 8951 个。
检查会话 :
ps -ef | grep -i $ORACLE_SID |wc -l
325
检查操作系统总共打开的文件描述符数量 :

从上面可以看到数据库会话总共 3 25 个 ,如果按照 每个会话打开 8 985 个左右的文件描述符 ,那么只需要 7 00 个左右的会话 , 就可以达到file-max 限制 。
数据库在dedicated server 模式并且使用 AMM 的情况下 :
根据MOS 上面提供的计算规则 , 每个会话默认会打开MEMORY_TARGET/<granule size> 个文件描述符 , 即 /dev/shm 中的文件数, 根据上面的数据库设置 , 5 8 * 1024/4 大概是 14848 多个文件描述符 , 跟上面 8 000 多个描述符是有差异的 。
granule size 查询:
select bytes /1024/1024 from v$sgainfo where name like 'Granule Size';
所以 ,这个计算规则是有问题的,经过测试,实际使用的文件描述符是使用 SGA 大小进行计算的,数据库启动 SGA 大小默认使用 MEMORY_TARGET * 60 % ,如果使用 MEMORY_TARGET * 60 %* 1024/4 方式计算 , 可以得出大概是8900 多个文件描述符 。
总结 :操 作系统 10:50:21 时间点报错 , 随后10:50:28 数据库报错 。所以 我们可以判断本次的故障是由于在故障时间点会话数上涨 (包括 活动和非活动的会话 ),并且会话没有及时释放连接, 从而导致打开的文件描述符达到file-max 限制 , 最终导致oracle 出现问题 。
解决办法和建议
1. 调整oracle 用户的 open files , 已经进行调整 。
2. 建议关闭AMM ,考虑 使用 自动共享内存管理 (ASMM) 和自动 PGA 管理,推荐采用这种方式。
参考命令 :
alter system set memory_target=0 scope=spfile;
alter system set memory_max_target=0 scope=spfile;
alter system set sga_max_size= XXX scope=spfile;
alter system set sga_target= XXX scope=spfile;
alter system set pga_aggregate_target= XXX scope=spfile;
。。。。
3. 建议调整 / dev/shm 大小 , 可以考虑从目前的 3 8G 调整到同 MEMORY_TARGET 参数值同样的大小 ,不 推荐 。
4. 考虑调整file-max 参数值大小 , 根据MEMORY_TARGET 和会话数综合进行判断 , 不推荐 。
5. /dev/shm 中 产生 的文件数 跟 memory_target 有关, file-max 和 shm 中文件数限制了 session 连接数,比如该例中 session 连接数上限为 762= 6815744 /8950
参考
Why Does Oracle Create So Many Open File Descriptors in /dev/shm on Linux When memory_target is Set ? (Doc ID 1321306.1)











