背景 PostgreSQL 调用 函数执行到第 6次,执行时间明显提高,检查了sql语句和索引,都没发现问题。 排查思路 之前了解到 Oracle有个绑定变量窥视功能,会影响到执行计划,顺着这个思路去了解PostgreSQL绑定变量在执行计划这块有什么区别。 绑定变量原理说明 首先大致说明一下绑定变量含义,类似于把执行计划缓存起来,下次执行的时候免去 parser这些阶段,提升速度。相较于Oracle,PostgreSQL有一个五次机制。如下:
l 当前 5次执行时,每次都会根据实际传入的实际绑定变量新生成执行计划进行执行,即每次都是硬解析,同时会记录这5次的执行计划。
l 当第 6次开始执行时,会生成一个通用的执行计划(generic plan),同时与前5次的执行计划进行比较,如果比较的结果是通用执行计划不比前5次的执行计划差 , 以后就会固定把这个通用的执行计划固定下来,这之后即使传入的值发生变化后,执行计划也不再变化。
l
当然,当第
6次开始执行时,如果通用的执行计划(generic plan)比前5次的某一个执行计划差,则以后则每次都重新生成执行计划,即以后永远都是硬解析了。
测试验证
我们先来看一个例子,创建一张
test表,其中有两列分别为id、info,在id列就2个值,一个值是"1",有500000行;另一个值是"2",只有1行。这个就是我们常说的数据分布倾斜问题。
 1.
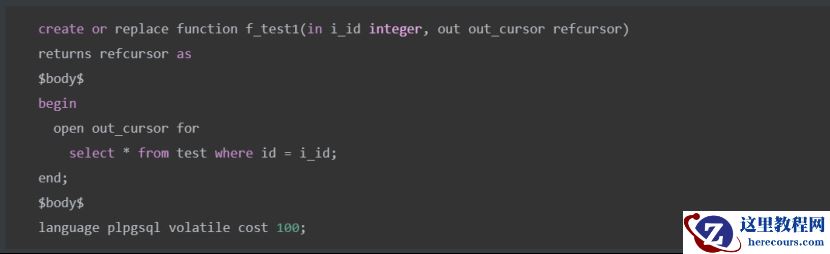
创建函数
1.
创建函数
2.
配置
auto_explain模块,
打印
执行计划
3.
执行
以
下语句
4.
通过日志文件查看执行计划
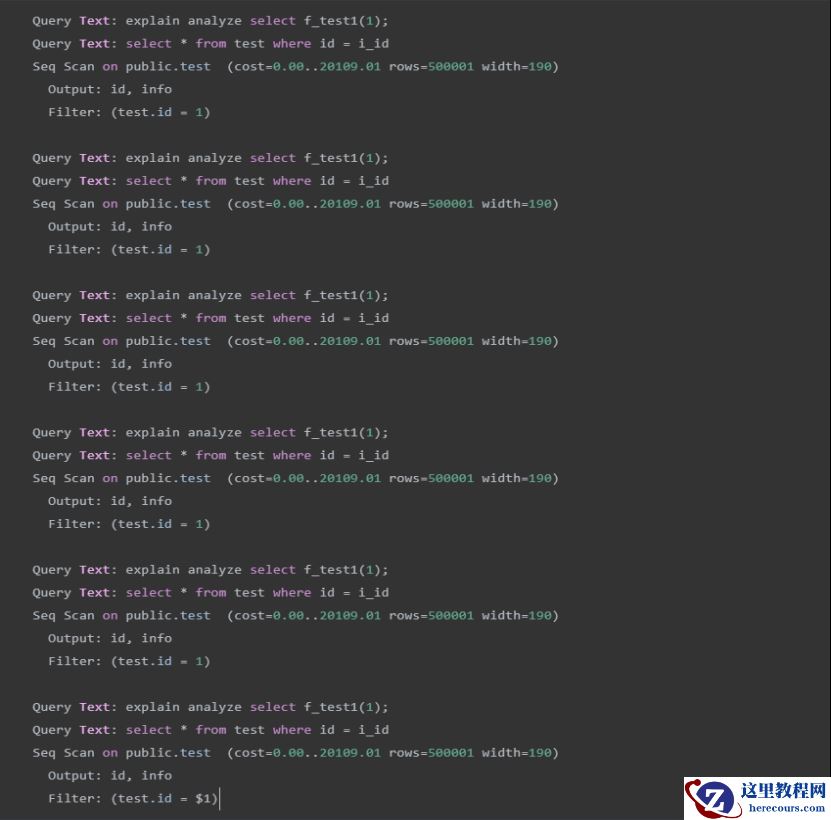 注意上面执行中的第
6次的执行计划和第5次的执行计划发生了变化
,
前
5次都是“Filter: (test.id = 1)”,而第6次变成了“Filter: (test.id = $1)”,这说明执行计划变成了通用执行计划,并使用绑定变量,这时把值改成“2”,发现也是走全表扫描,不走索引。
注意上面执行中的第
6次的执行计划和第5次的执行计划发生了变化
,
前
5次都是“Filter: (test.id = 1)”,而第6次变成了“Filter: (test.id = $1)”,这说明执行计划变成了通用执行计划,并使用绑定变量,这时把值改成“2”,发现也是走全表扫描,不走索引。

5.
为什么第六次才生成通用执行计划?
我们可以在
PostgreSQL的plancache.c源码中找到说明:
 请注意,这里的限定值小于
5次,返回true,选择custom执行计划,而大于5次之后,则选择通用执行计划。因此,5次之后执行计划就会固定。
解决方案
1.
修改函数的写法,如下:
请注意,这里的限定值小于
5次,返回true,选择custom执行计划,而大于5次之后,则选择通用执行计划。因此,5次之后执行计划就会固定。
解决方案
1.
修改函数的写法,如下:
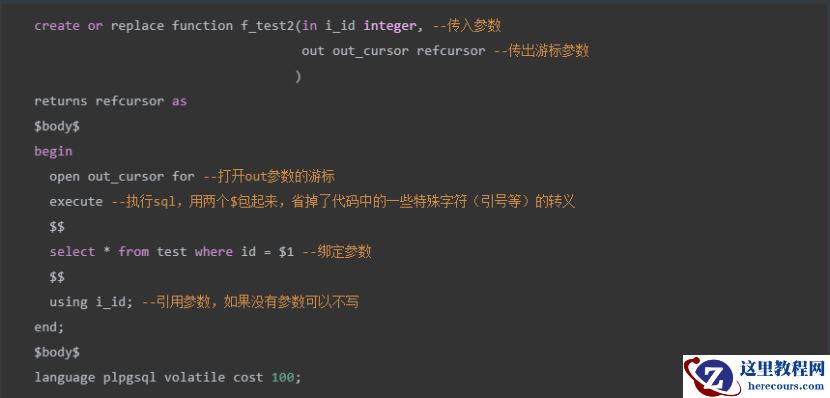
2.
再次
执行
以
下语句
3.
通过日志文件查看执行计划
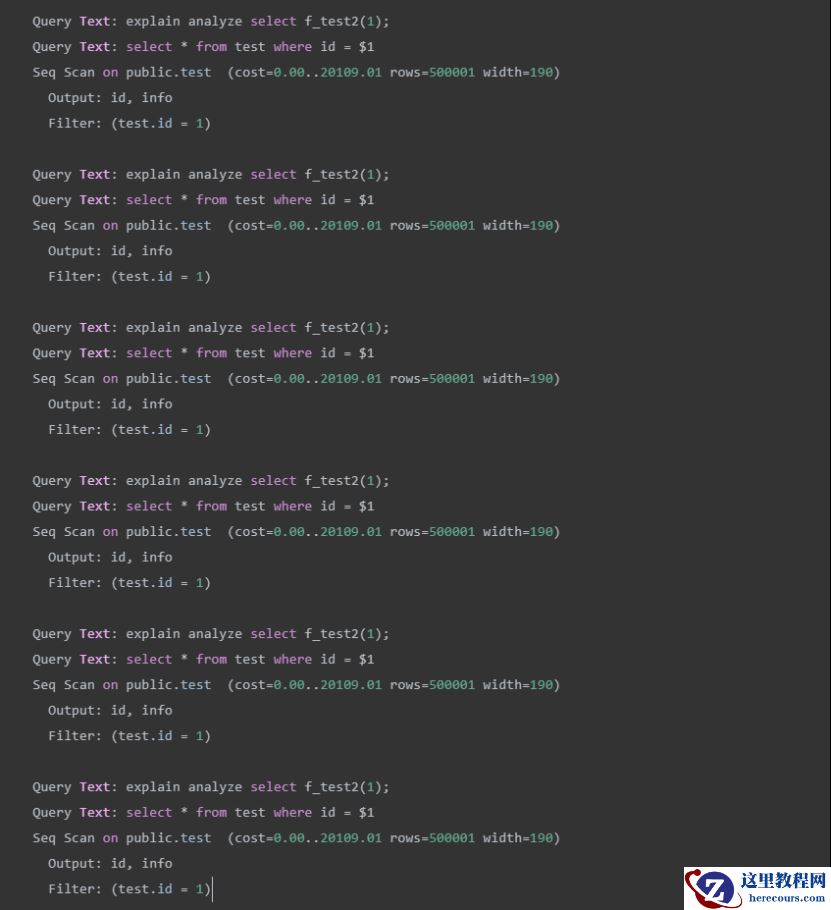 注意上面执行中的第
6次的执行计划
,
“Filter: (test.id = 1)”
没变
,这说明
重新生成
执行计划,这时把值改成
“2”,发现
不
走全表扫描,走索引
了
。
注意上面执行中的第
6次的执行计划
,
“Filter: (test.id = 1)”
没变
,这说明
重新生成
执行计划,这时把值改成
“2”,发现
不
走全表扫描,走索引
了
。
 结论
结论
综上所述,如果表的数据分布非常倾斜需要特别注意,在数据分布不均匀的字段上使用绑定变量,可能会出现数据库性能问题。建议对于数据倾斜的情况,采用以上解决方案来修改函数。









")

