添加 ASM 磁盘故障
问题背景
近期处理了 2 起 ASM 添加磁盘出现的故障,问题现象类似,处理方式也类型。存在共性,所以整理了下相关故障信息,做了一些总结,希望能对大家带来一些参考意义。
故障分析与处理
案例一、某客户
1.1、问题分析
增加磁盘,日志中可以看到已经成功完成磁盘组中
disk
的添加
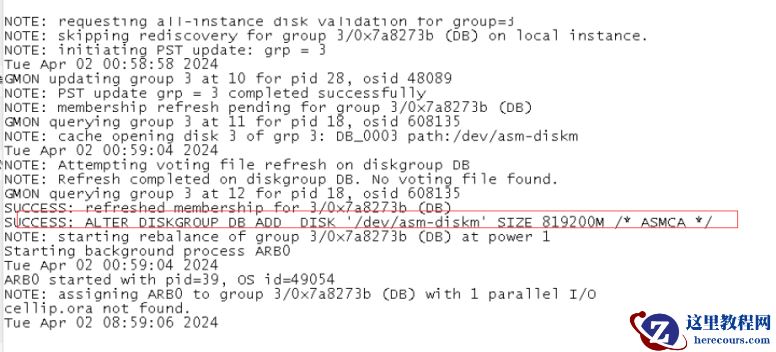 半个小时后,磁盘头异常:报
ORA-15196
错误,提示
ASM
块头无效。
半个小时后,磁盘头异常:报
ORA-15196
错误,提示
ASM
块头无效。
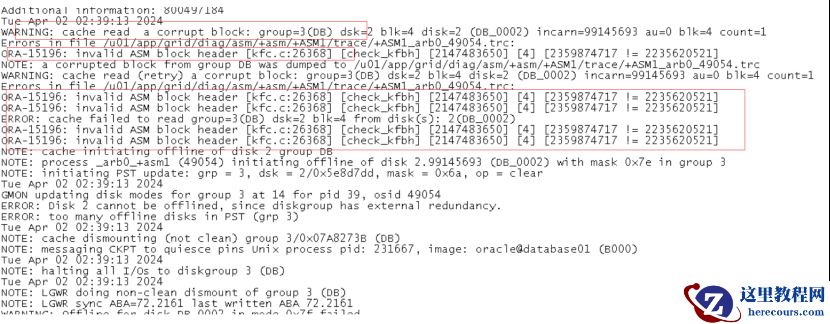 Rebanlence
过程中,突然
asm
磁盘头故障:
Rebanlence
过程中,突然
asm
磁盘头故障:
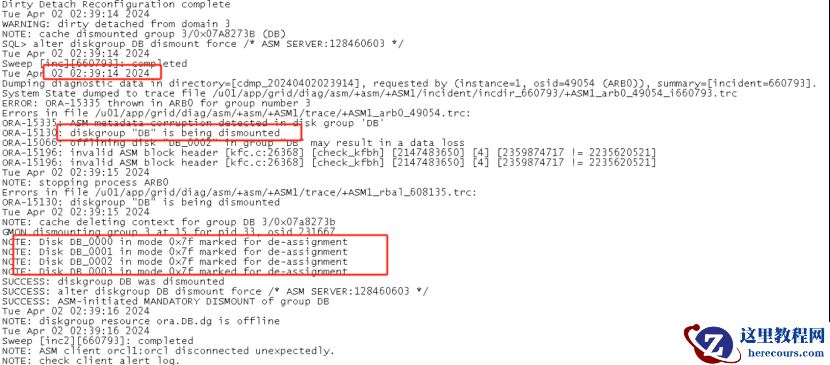
 接着磁盘组
dismount
,磁盘被标记为“
de-assignment
”
接着磁盘组
dismount
,磁盘被标记为“
de-assignment
”
 通过查询官网,可以看到
BUG
造成。
通过查询官网,可以看到
BUG
造成。
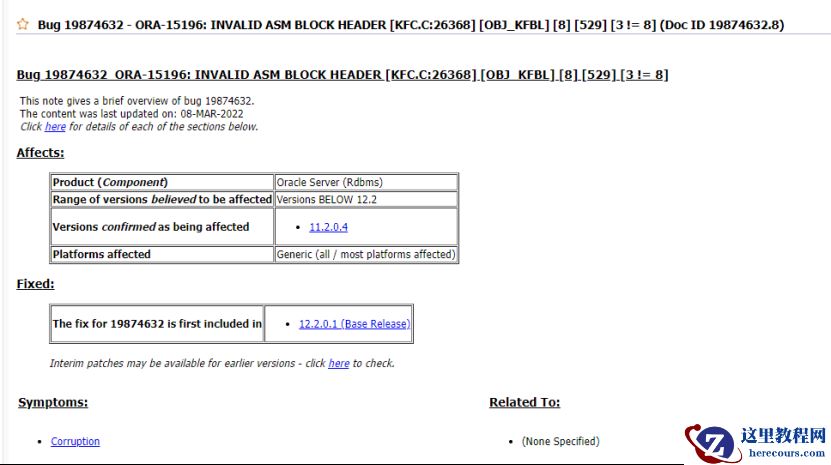 增加磁盘出现问题
增加磁盘出现问题
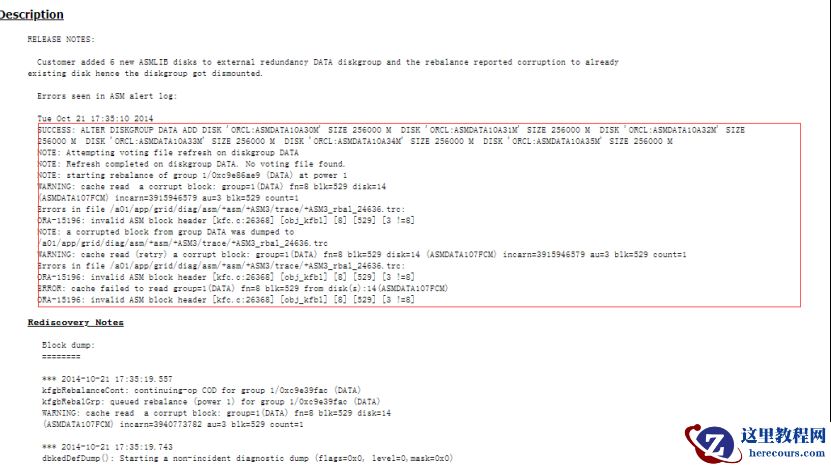 只能重建磁盘组恢复:
只能重建磁盘组恢复:
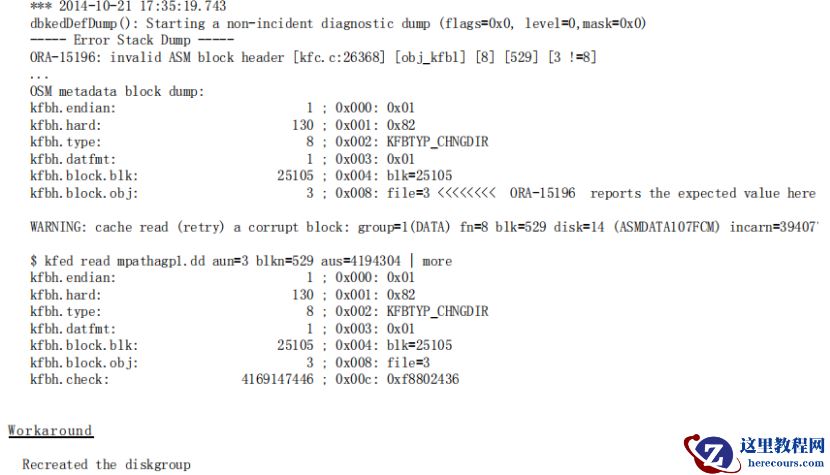
1.2、问题处理
l 切换 dg(...过程略)
l 老生产禁用和停止相关服务,避免业务连接到老生产 srvctl disable scan_listener srvctl disable scan srvctl disable listener -n test1 srvctl disable listener -n test2 srvctl disable vip -n test1 srvctl disable vip -n test2 停 scan监听 srvctl stop scan_listener 停 scan vip srvctl stop scan 关监听和 VIP服务 srvctl stop listener -n rac1 srvctl stop vip -n rac1 srvctl stop listener -n rac2 srvctl stop vip -n rac2 检查 ip地址,scan ip和vip是否下掉,并重启验证。
l 重建老库磁盘组 检查 db磁盘组的磁盘,并dd掉对应的磁盘头 select * from v$asm_disk; 如: dd if=/dev/zero of=/dev/asm-diskm bs=1024k count=100 重建磁盘组: create diskgroup DB external redundancy disk '/dev/asm-diskl','....','/dev/asm-diskm' attribute 'compatible.asm'='11.2.0.0.0';
l 单独启动 db监听(...过程略)
l 搭建 dg(...过程略)
案例二
客户数据库由于出现归档日志异常增长现象,导致 asm 磁盘组空间被撑满。应急处理删除部分归档,后续规划进行磁盘组扩容,计划晚上添加磁盘。
客户提供了 2 块 1T 共享盘,当晚完成了 ASM 扩容,扩容后客户反馈,业务出现了业务无法连接。排查发现实例宕了, DATA 磁盘组无法 mount 。
2.1、问题 分析
1、 ASM告警日志
问题时间出现告警, DATA 磁盘组成员盘 newdata03(DATA_0000) 异常导致磁盘
组无法挂载。磁盘头异常:报
ORA-15196
错误,提示
ASM
块头无效
,
同时伴随其
ORA
报错。
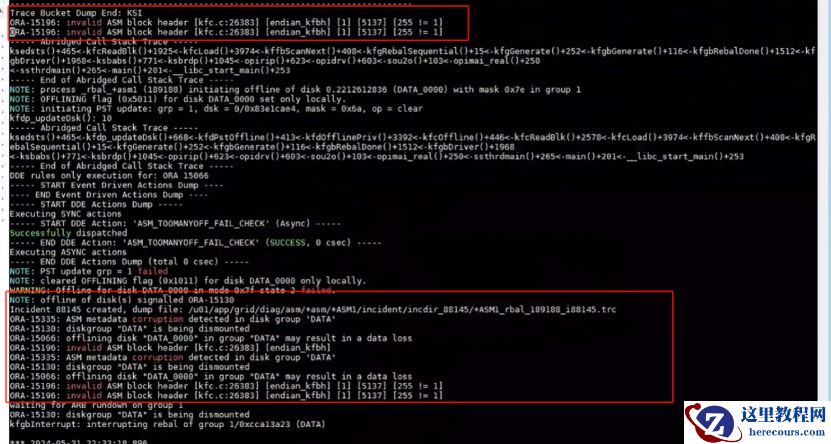
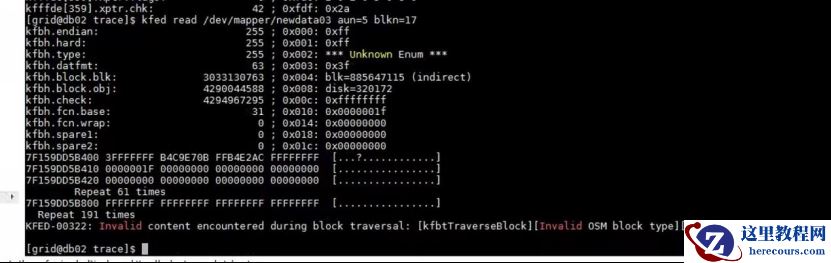
2、 磁盘权限及磁盘报错 au块检查
通过
kfed
检查磁盘权限正常。磁盘对应
au
块显示损坏
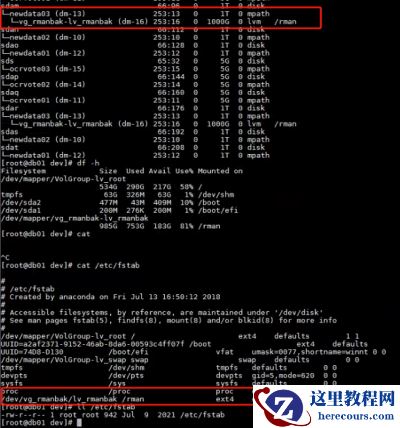
3、 系统磁盘检查
排查发现新增
DATA
磁盘组成员盘
newdata03(DATA_0000),
在系统上已经作为
rman
备份
lv
在使用。由此导致了
DATA
磁盘组的状态异常。
2.2、问题处理
检查备份,只有 2024 年 5 月 30 日的备份片。客户反馈无容灾库。尝试拉起 data 磁盘组失败。报磁盘头问题以及 au=5 blk=0 、 au=5 blk=17 损坏。
设置 events 尝试强制 mount 磁盘组,启动成功。取出归档,打算使用老的备份片加归档在其他环境恢复。 SQL> alter system set events '15195 trace name context forever, level 604'; SQL> alter system set asm_power_limit = 0;
经过仔细盘查和确认后,客户发现该库是存在 dg 备库,检查后,发现满足切换条件,进行了备库强制打开、扩容资源、更换 IP 做临时库使用,支撑院内业务。
后续将临时单机库与修复好的老生产库搭建 dg ,于 2024 年 6 月 4 日晚业务空闲时间切换,让业务重新回归老的 rac 环境。
技术原理
asm 添加盘或者踢盘时,要检查 v$asm_operation , 另外 rebanlence 过程是分三个阶段的:
1) 第一阶段: planning 阶段需要的时间是非常少的。
2) 第二阶段: extent relocation 一般会占取 rebalance 阶段的大部分时间,可以看到估值的时间 EST_MINUTES 单位为分钟, ASM 的 alert 会有显示 rebalance 。
NOTE: membership refresh pending for group 1/0x6ecaf3e6 (DATA) GMON querying group 1 at 32 for pid 19, osid 38421 SUCCESS: refreshed membership for 1/0x6ecaf3e6 (DATA) NOTE: Attempting voting file refresh on diskgroup DATA
有上面日志说明二阶段完成。
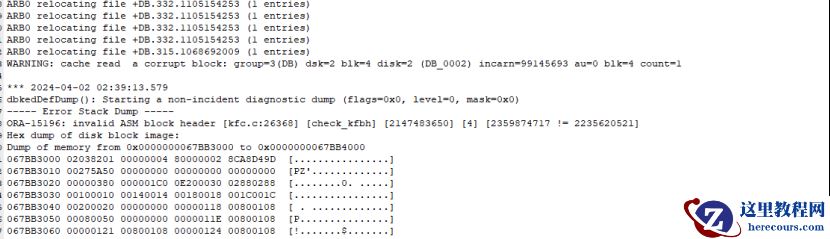
3) 第三阶段: compacting 阶段, EST_MINUTES 变成 0 ,检查日志 +ASM2_arb0_10593.trc ,通过 tail 命令查看 ARB0 的跟踪文件,发现 relocating 正在进行,而且一次只对一个条目进行 relocating 。
*** 2023-08-23 18:18:23.540 ARB0 relocating file +DATA.91169.1119274161 (1 entries)
一旦 compacting 阶段完成, ASM 的 alert 日志中会显示 stopping process ARB0 和 rebalance completed:
compact 操作是指尽可能的让 extents 磁盘外圈挪动,读取数据可以获得更快的速度
建议总结
针对添加磁盘出现的 ORA-15196 错误,目前官方文档表示没有有效快速的修复方案,所以总结下来主要有以下规避和解决方案。
添加磁盘前,检查,避免出问题
1 、检查数据库是否有备份或者容灾可用
asm 添加磁盘存在 bug 风险,尽管几率非常低,但在添加磁盘时,还是要检查备份或者容灾是否正常,防止磁盘故障,无法段时间内恢复,但是需要尽快恢复业务可用。如果允许,建议创建新的 asm 磁盘组,不要在原来的磁盘组上添加。
2 、检查需要添加的磁盘是否已经使用
asm 添加盘时要检查,待添加的共享磁盘是否已经被使用,同样添加文件系统的时候也要注意不要把 asm 的共享盘使用掉。可以通过 lsblk 查看有没有分区和挂载文件系统, grid 用户下“ kfod di=all ”去查看 asm 识别的盘。
添加磁盘时出问题
1、 切容灾,第一时间恢复业务,确保业务连续性。这个是优先选择,否则尝试下面步骤
2、 可以尝试通过设置 events 15195 来强制 mount 磁盘组,如果成功,需要尽快导出相关数据 / 文件,然后重建磁盘组或者 DB 。
3、 可以尝试通过 kfed 来修复磁盘
4、 dd 掉磁盘,重建磁盘组。





")






