前几天,客户反应,在备库俩节点执行同一条SQL的效率差别很大,一节点1秒内完成,二节点需要接近三秒。这个SQL是他们探测数据库性能的监控语句,接近三秒返回结果很显然是没达标的。
------------- SQL Text -------------- select * from uap_xxx_view v where v.账号=:"SYS_B_0" ------------- SQL Plan (Plan Hash Value:493815505; Parsed by schema:xxx) -------------- 0 ( )SELECT STATEMENT Optimizer=ALL_ROWS (Cost=73) 1 (0) NESTED LOOPS (Cost=73 Card=1 Bytes=2207) 2 (1) NESTED LOOPS (Cost=3 Card=1 Bytes=90) 3 (2) TABLE ACCESS (BY INDEX ROWID) OF 'Pxx_ACCOUNT' (TABLE) (Cost=2 Card=1 Bytes=64) *4 (3) INDEX (UNIQUE SCAN) OF 'UxxNAME' (INDEX (UNIQUE)) (Cost=1 Card=1) 5 (2) TABLE ACCESS (BY INDEX ROWID) OF 'PxxS' (TABLE) (Cost=1 Card=1 Bytes=26) *6 (5) INDEX (UNIQUE SCAN) OF 'SYS_C0019193' (INDEX (UNIQUE)) (Cost=0 Card=1) #7 (1) VIEW OF 'ORxxA' (VIEW) (Cost=70 Card=1 Bytes=2117) #8 (7) FILTER *#9 (8) CONNECT BY (NO FILTERING WITH START-WITH) #10 (9) TABLE ACCESS (FULL) OF 'OxG' (TABLE) (Cost=70 Card=5794 Bytes=156438)
大致的执行计划就如上面所示,俩节点的执行计划都是一摸一样的,懂得哥们自然第一反应就是和GC相关了。这是对的,确实在问题节点上,GC等待:gc cr multi block request 占了大部分内容,那么如何去解决处理呢? 这边先介绍下查询对象,这是一个视图,视图里面有两张表和另一张视图(最恶的视图套视图),其实涉及的数据量都不大的,没道理会产生GC等待,并有这么大的执行效率上的差异,当时怀疑的有BUG在里边(事后证明是对的)。但即使是有BUG,碍于生产环境不便打补丁,那么如何通过SQL层面去解决处理? 首先了解下 gc cr multi block request这个等待事件,这个等待是很常见的,就不赘述了,大致上就 是RAC数据库上比较常见的一种等待事件,在RAC上进行全表扫描(Full Table Scan)或者全索引扫描(Index Fast Full Scan)时,容易产生这样的 多块读等待。 我把多快读标红了,说明这就是我们解决问题的突破口。在上面提供的执行计划中,其实就是第10步的全表扫描导致的多块读继而引发的GC等待BUG,我们就要想办法让他取走单块读或者直接从盘上抽数据而不是走内存融合。那么就分为两种解决问题的思路:1、不要多快读 2、不要内存融合。 考虑到不走内存融合的方式,可能会影响到其他的业务模块,于是便把思路主要放在第一种方式上。 其中把信息脱敏后,主要问题就出现在下面的语句上,这是经过脱敏的内容,不影响阅读。
select * from xxx o where o.xxx_name not in ('111','222','333','444')
该语句的写法导致执行计划变为o.xx<>111..222..333..444等内容,这样是无法走索引的,而我们需要通过索引的访问路径来尝试单块读,变作出如下改写:
SELECT * FROM xxx o WHERE NOT EXISTS ( SELECT 1 FROM ( SELECT '111' AS exclude_name FROM DUAL UNION ALL SELECT '222' FROM DUAL UNION ALL SELECT '333' FROM DUAL UNION ALL SELECT '444' FROM DUAL ) ex WHERE o.xxx_name = ex.exclude_name )
然后在xxx_name列上创建索引,成功使得访问路径变为了INDEX FULL SCAN的方式,该方式是单块读抽取数据,经过测试后发现二节点返回结果时间也降至了1秒内。
该案例可能看起来很简单,但主要的是解决问题的思路,沿着该思路其实还有一种解决问题的方式就是,在执行该语句前,统一在会话级设置参数"
db_file_multiblock_read_count=1"。优化其实就是思路的具象体现,所以为什么说优化永不过时,因为思路不会过期。
反正临时的解决方案已出,剩下的就是交给业务抉择了,下班下班!
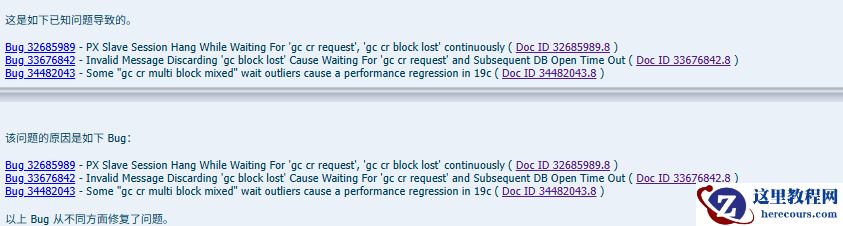
PS:附上BUG贴图




")



