一、故障初现:应用卡顿紧急排查
某医疗客户核心 HIS 系统夜间突发应用卡顿,诊疗业务响应迟缓,严重影响医院正常诊疗流程。我方 DBA 接报后迅速登录数据库服务器,启动紧急排查工作。
排查初期, DBA 优先聚焦数据库核心等待事件,通过反复执行如下 SQL 语句监控活跃会话状态:
select username, program, inst_id, sid, serial#, sql_id, event, final_blocking_session final_bs, final_blocking_instance final_bi, wait_class, SECONDS_IN_WAIT, LAST_CALL_ET from gv$session where wait_class <> 'Idle' order by SECONDS_IN_WAIT desc;
执行过程中发现一个关键异常:该查询返回结果时快时慢,快速响应时瞬间返回,延迟时卡顿达 5 秒以上,且延迟状态下会出现大量 library cache lock 等待事件。通过持续观察会话关联的 SQL_ID , DBA 锁定核心可疑对象 ——SQL_ID:9zg9qd9bm4spu ,初步判断其为本次卡顿的根源。
二、定位:Oracle Bug 引发的基表更新异常
针对 SQL_ID:9zg9qd9bm4spu 展开深度分析,其对应的 SQL 文本为:
update user$ set spare6=DECODE(to_char(:2, 'YYYY-MM-DD'), '0000-00-00', to_date(NULL), :2) where user#=:1
该 SQL 由 HIS 系统业务用户发起,但核心疑点在于:业务用户正常操作应访问业务表,而非直接更新 Oracle 系统基表 user$ 。这一异常行为引发 DBA 警惕,随即通过 Oracle MOS 文档及外部技术社区检索,最终明确该问题源于 Oracle 已知 Bug ( Bug 号: 33121934 ),且故障数据库版本( 19c )正处于该 Bug 的影响范围,官方已提供针对性修复补丁。
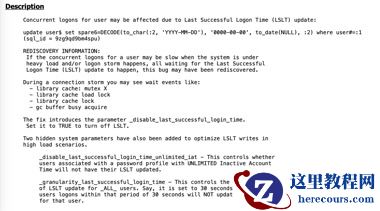
进一步查阅补丁说明得知:该补丁支持 RAC 环境滚动安装,但需前提条件 —— 数据库已应用 19c 版本 19.15.0.0.220419DBRU 的补丁集更新( PSU 33806152 )。 RAC 滚动安装流程如下:
1 、关闭目标节点 Oracle 主目录下所有服务(含数据库、 ASM 、监听器、节点应用程序及 CRS 守护进程); 2 、执行 opatch apply -local 命令在本地节点安装补丁; 3 、启动该节点所有服务,对其他节点重复上述步骤(单次仅操作一个节点)。
经与医院方紧急沟通,获得即时打补丁授权后, DBA 按流程完成双节点滚动安装,并根据 MOS 指引设置隐藏参数使其即时生效:
alter system set "_disable_last_successful_login_time"=true;
参数生效后, library cache lock 等待事件彻底消失, SQL_ID:9zg9qd9bm4spu 不再出现, DBA 初步判定问题已解决。
三、二次故障:集群通信引发的新等待事件
然而故障排查并未就此结束 ——library cache lock 消失后,数据库出现新的异常:等待事件查询仍时快时慢,延迟时卡顿超 5 秒,且大量 gc buffer busy acquire 等待事件涌现。通过会话关联分析,所有异常等待均指向 SQL_ID:d2217udafsm66 ,其 SQL 文本为:
select count(*) from link_sources$ where username = :uname
gc buffer busy acquire 等待事件的核心指向 RAC 集群通信、内存融合或跨节点数据访问问题。 DBA 首先排查集群心跳网络,通过 ping 命令测试心跳链路,初期未发现延迟或丢包现象,暂时排除网络基础问题。
随后, DBA 全面核查集群日志、实例告警日志等关键文件,均未找到有效故障线索。为进一步定位问题,在医院方同意后启动单节点测试:
1、关闭节点一数据库实例,仅保留节点二数据库实例运行:等待事件查询正常,无gc buffer busy acquire; 2、关闭节点二数据库实例,仅保留节点一数据库实例运行:等待事件查询正常,无异常等待。
测试结果验证了核心推测: gc 相关等待仅在双节点同时运行时出现,确属集群跨节点通信引发的问题。
四、意外突破:硬件故障暴露网络隐患
为尝试解决集群通信问题, DBA 决定重启其中一台服务器硬件。但重启后该节点集群无法正常启动,报出关键错误:
CRS-7503: The Oracle Grid Infrastructure process 'ocssd' observed comunication issues between node 'rac1' and node 'rac2',interface list oflocal node 'rac1'is 'xxx.xx.19.1:42217;', interface list of remote rac2'xxx.19.19.2:51138;'
该报错与此前 ping 测试结果矛盾 —— 明明测试无网络问题,却出现明确的节点间通信异常。 DBA 立即重新执行心跳链路 ping 测试,结果令人意外:多次测试中,心跳包丢包率高达 30%~50% ,彻底推翻此前的网络正常判断。
医院方迅速联系硬件厂商介入排查,最终定位故障根源:服务器光模块损坏导致心跳链路不稳定。当晚 3 点左右,新光模块更换完成, DBA 重启双节点集群后, gc buffer busy acquire 等待事件完全消失,等待事件查询响应迅速稳定, HIS 应用卡顿现象彻底解决。
五、故障复盘:根源追溯与逻辑梳理
事后深度分析揭示了故障的完整逻辑链:
-
潜在问题铺垫:
SQL_ID:9zg9qd9bm4spu
对应的
user$
表更新异常,源于
Oracle Bug 33121934
,此问题在之前数据库巡检中已被
DBA
关注到,但未引发明显故障;
网络问题放大:服务器光模块损坏导致集群心跳链路丢包率达
30%~50%
,这一核心硬件故障放大了此前存在的
Bug
影响,引发大量
library cache lock
等待,直接导致应用卡顿;
故障暴露递进:当补丁修复
Bug
后,网络故障的影响不再被掩盖,转而通过
gc buffer busy acquire
等待事件显现,且该事件与
dblink
相关
SQL
(
d2217udafsm66
)关联,进一步印证集群通信问题;
最终根源确认:单节点测试正常、双节点异常的现象,结合集群启动报错,最终锁定心跳链路故障,而光模块损坏是网络异常的根本原因。
六、案例结论与经验总结
-
故障根源:本次
HIS
数据库卡顿的核心原因是服务器光模块损坏导致的集群心跳链路丢包,
Oracle Bug 33121934
仅为次要影响因素,且被网络故障放大;
排查关键:
RAC
环境中
gc
系列等待事件需优先排查集群通信(心跳链路、网络设备),单节点
/
双节点对比测试是定位集群相关问题的高效方法;
补丁应用:应用
Oracle
补丁前需严格核查前提条件(如
PSU
版本),滚动安装需遵循
“
单节点操作、依次推进
”
原则,避免影响集群可用性;
隐患警惕:巡检中发现的异常
SQL
或潜在问题需跟踪处理,此类问题可能在特定条件(如硬件故障)下被放大,引发严重业务影响;
网络验证:
ping
测试需多次执行并统计丢包率,单次测试结果可能存在偶然性,无法全面反映网络稳定性。

编辑推荐:
- 医疗HIS数据库双节点故障排查实战案例03-03
- 内测分发是什么?03-03
- PyTorch实战:手把手搭建CV模型全流程03-03
- Oracle从HPUX迁移至Linux的经验教训03-03
- 第50期 OGG在现有进程中新增一个同步表的流程03-03
- 在发布应用程序内测时如何选择合适的分发上架方式?03-03
- RAC 容灾环境归档传输异常溯源03-03
- 应用APP开发程序编辑中的数据加密和解密以及签名使用解释技巧03-03
相关推荐
-

-
-
-
-
-
-
-
-
-
-
-
-
-
-

雷神推出 MIX PRO II 迷你主机:基于 Ultra 200H,玻璃上盖 + ARGB 灯效
2 月 9 日消息,雷神 (THUNDEROBOT) 现已宣布推出基于英
-

制造商 Musnap 推出彩色墨水屏电纸书 Ocean C:支持手写笔、第三方安卓应用
2 月 10 日消息,制造商 Musnap 现已在海外推出一款 Oce
")

热文推荐
- 医疗HIS数据库双节点故障排查实战案例

医疗HIS数据库双节点故障排查实战案例
26-03-03 - RAC 容灾环境归档传输异常溯源

RAC 容灾环境归档传输异常溯源
26-03-03 - 数据库管理-第376期 Oracle AI DB 23.26新特性一览(20251016)
- 第51期 OGG执行Send Extract Showtrans在数据库中不存在 XIDs
- 数据库管理-第377期 26ai的线下部署版本真的是“慢半拍”么(20251018)
- oracle 备库归档日志某一天突发暴增到2000多个

oracle 备库归档日志某一天突发暴增到2000多个
26-03-03 - Oracle RMAN三种不完全恢复实战详解:归档序号、时间点与SCN恢复对比
- 数据库管理-第373期 23ai:变化,不支持的功能与参数(20251011)
- Oracle 常见的33个等待事件

Oracle 常见的33个等待事件
26-03-03 - 第47期 OGG DownStream 部署

第47期 OGG DownStream 部署
26-03-03
")

")