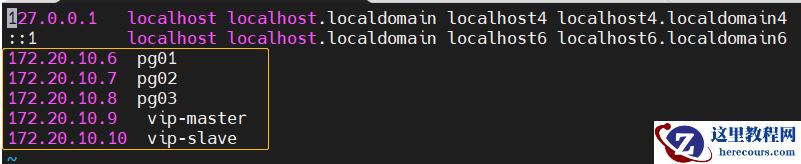
地址信息 172.20.10.6 pg01 172.20.10.7 pg02 172.20.10.8 pg03 172.20.10.9 vip-master 172.20.10.10 vip-slave
hosts文件如下
一、三台机器同步时间
[root@ysl01 ~]# ntpdate ntp1.aliyun.com 12 May 13:31:04 ntpdate[1571]: adjust time server 120.25.115.20 offset -0.003524 sec
二、安装依赖包和集群软件
1.三个节点均安装依赖包和集群软件
yum install -y pacemaker corosync pcs
其中, pacemaker 为Linux环境中使用最为广泛的开源 集群资源管理器, Pacemaker利用集群基础架构(Corosync或者 Heartbeat)提供的消息和集群成员管理功能,实现节点和资源级别的故障检测和资源恢复,从而最大程度保证集群服务的高可用。是 整个高可用集群的控制中心,用来管理整个集群的资源状态行为。客户端通过 pacemaker来配置、管理、监控整个集群的运行状态。
Corosync集群引擎是一种群组通信系统(Group Communication System),为应用内部额外提供支持高可用性特性。corosync和heartbeat都属于消息网络层, 对外提供服务和主机的心跳检测,在监控的主服务被发现当机之后,即时切换到从属的备份节点,保证系统的可用性。一般来说都是选择corosync来进行心跳的检测,搭配pacemaker的资源管理系统来构建高可用的系统。
pcs是Corosync和Pacemaker 配置工具。它 允许用户轻松查看,修改和创建基于Pacemaker的集群。pcs包含pcsd(一个pc守护程序),它可作为pc的远程服务器并提供Web UI。全部受控的 pacemaker和配置属性的变更管理都可以通过 pcs实现。
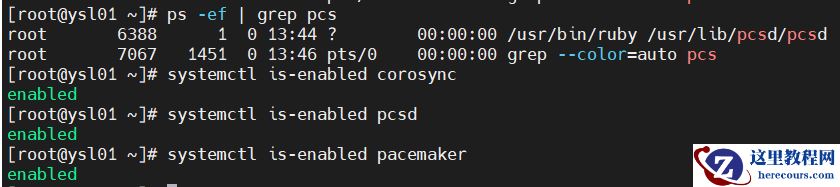
2.启动服务
systemctl start pcsd systemctl enable pcsd systemctl enable corosync systemctl enable pacemaker
三、启动集群
1.设置hacluster用户密码(三个节点)
echo hacluster|passwd hacluster --stdin

2.集群认证(在任何一个节点上执行)
pcs cluster auth -u hacluster -p hacluster pg01 pg02 pg03

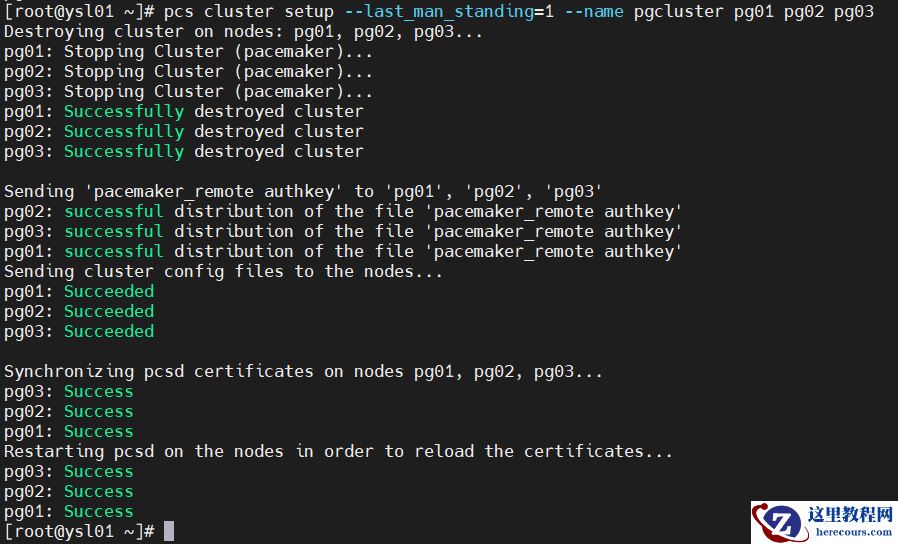
3.同步配置(在任何一个节点上执行)
pcs cluster setup --last_man_standing=1 --name pgcluster pg01 pg02 pg03
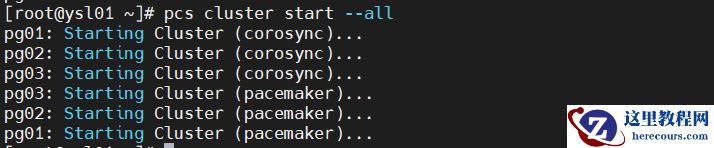
4.启动集群(在任何一个节点上执行)
pcs cluster start --all
四、安装PostgreSQL数据库(三个节点)
1.安装依赖
yum install -y openssl openssl-devel readline readline-devel zlib-devel gcc flex
2.创建用户
groupadd dba -g 1100 useradd postgres -g 1100 -u 1100

3.安装数据库
1.获取并解压包
su - postgres wget https://www.postgresql.org/ftp/source/v11.10/postgresql-11.10.tar.gz --no-check-certificate tar -xf postgresql-11.10.tar.gz
2.编译安装(三个节点)
进入目录
cd postgresql-11.10/
./configure --prefix=/home/postgres/soft make world -j24 make install-world -j24
3.初始化数据库数据目录到/home/postgres/data(master节点)
/home/postgres/soft/bin/initdb -D /home/postgres/data
4.配置环境变量
vi .bashrc
export PGUSER=postgres
export PGHOME=/home/postgres/soft
export PGDATA=/home/postgres/data
export PATH=${PGHOME}/bin:${PATH}
LD_LIBRARY_PATH=$PGHOME/lib:/usr/local/lib:/usr/local/lib64:/usr/lib64:$LD_LIBRARY_PATH
source .bashrc
5.修改配置文件和hba
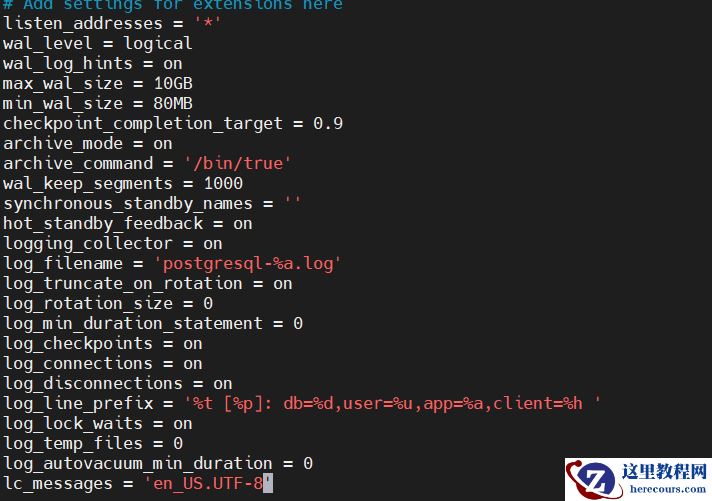
postgresql.conf:
listen_addresses = '*' wal_level = logical wal_log_hints = on max_wal_size = 10GB min_wal_size = 80MB checkpoint_completion_target = 0.9 archive_mode = on archive_command = '/bin/true' wal_keep_segments = 1000 synchronous_standby_names = '' hot_standby_feedback = on logging_collector = on log_filename = 'postgresql-%a.log' log_truncate_on_rotation = on log_rotation_size = 0 log_min_duration_statement = 0 log_checkpoints = on log_connections = on log_disconnections = on log_line_prefix = '%t [%p]: db=%d,user=%u,app=%a,client=%h ' log_lock_waits = on log_temp_files = 0 log_autovacuum_min_duration = 0 lc_messages = 'en_US.UTF-8'
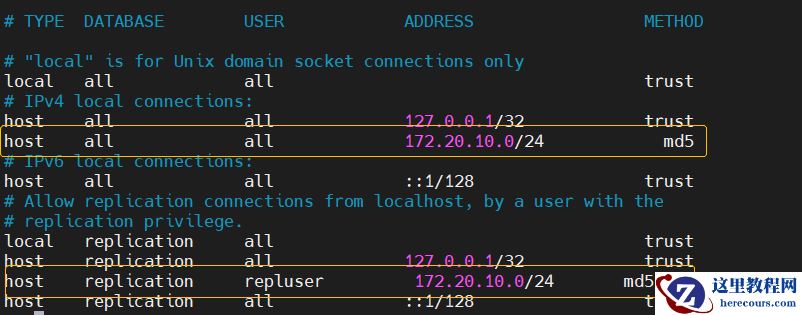
pg_hba.conf:
host all all 172.20.10.0/24 md5 host replication repluser 172.20.10.0/24 md5
6.启动master数据库
pg_ctl start -D /home/postgres/data
7.创建复制用户(master节点)
create user repluser with replication password 'repluser';

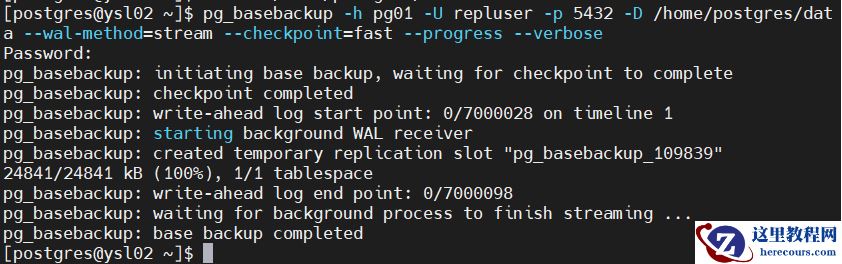
8.创建备机节点(pg02、pg03)
pg_basebackup -h pg01 -U repluser -p 5432 -D /home/postgres/data --wal-method=stream --checkpoint=fast --progress --verbose
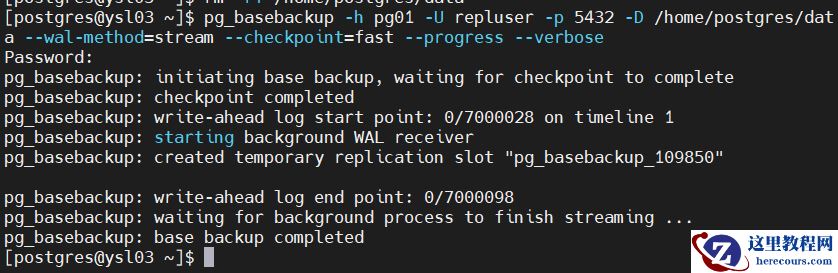
9.停止master(pg01)
pg_ctl stop -D /home/postgres/data

五、配置集群
1.配置cluster_setup.sh脚本
vim cluster_setup.sh
pcs cluster cib pgsql_cfg pcs -f pgsql_cfg property set no-quorum-policy="ignore" pcs -f pgsql_cfg property set stonith-enabled="false" pcs -f pgsql_cfg resource defaults resource-stickiness="INFINITY" pcs -f pgsql_cfg resource defaults migration-threshold="1" pcs -f pgsql_cfg resource create vip-mas IPaddr2 \ ip="172.20.10.9" \ nic="ens33" \ cidr_netmask="24" \ op start timeout="60s" interval="0s" on-fail="restart" \ op monitor timeout="60s" interval="10s" on-fail="restart" \ op stop timeout="60s" interval="0s" on-fail="block" pcs -f pgsql_cfg resource create vip-sla IPaddr2 \ ip="172.20.10.10" \ nic="ens33" \ cidr_netmask="24" \ meta migration-threshold="0" \ op start timeout="60s" interval="0s" on-fail="stop" \ op monitor timeout="60s" interval="10s" on-fail="restart" \ op stop timeout="60s" interval="0s" on-fail="ignore" pcs -f pgsql_cfg resource create pgsql pgsql \ pgctl="/home/postgres/soft/bin/pg_ctl" \ psql="/home/postgres/soft/bin/psql" \ pgdata="/home/postgres/data" \ config="/home/postgres/data/postgresql.conf" \ rep_mode="async" \ node_list="pg01 pg02 pg03" \ master_ip="172.20.10.9" \ repuser="repluser" \ primary_conninfo_opt="password=repluser keepalives_idle=60 keepalives_interval=5 keepalives_count=5" \ restart_on_promote='true' \ op start timeout="60s" interval="0s" on-fail="restart" \ op monitor timeout="60s" interval="4s" on-fail="restart" \ op monitor timeout="60s" interval="3s" on-fail="restart" role="Master" \ op promote timeout="60s" interval="0s" on-fail="restart" \ op demote timeout="60s" interval="0s" on-fail="stop" \ op stop timeout="60s" interval="0s" on-fail="block" \ op notify timeout="60s" interval="0s" pcs -f pgsql_cfg resource master msPostgresql pgsql \ master-max=1 master-node-max=1 clone-max=5 clone-node-max=1 notify=true pcs -f pgsql_cfg resource group add master-group vip-mas pcs -f pgsql_cfg resource group add slave-group vip-sla pcs -f pgsql_cfg constraint colocation add master-group with master msPostgresql INFINITY pcs -f pgsql_cfg constraint order promote msPostgresql then start master-group symmetrical=false score=INFINITY pcs -f pgsql_cfg constraint order demote msPostgresql then stop master-group symmetrical=false score=0 pcs -f pgsql_cfg constraint colocation add slave-group with slave msPostgresql INFINITY pcs -f pgsql_cfg constraint order promote msPostgresql then start slave-group symmetrical=false score=INFINITY pcs -f pgsql_cfg constraint order demote msPostgresql then stop slave-group symmetrical=false score=0 pcs cluster cib-push pgsql_cfg
sh cluster_setup.sh
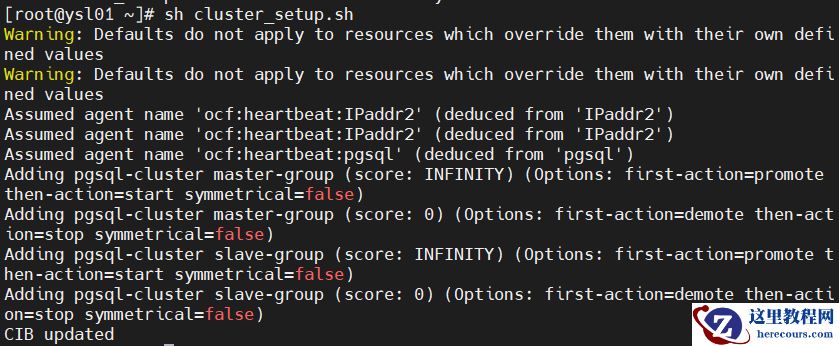
2.修改集群配置:
cibadmin --query > tmp.xml //将当前集群配置信息保存到tmp.xml文件中 cibadmin --query > tmp.xml vi tmp.xml //使用编辑器对XML文件进行修改 vim tmp.xml cibadmin --replace --xml-file tmp.xml //将修改后的XML文件替换掉当前集群的配置信息 cibadmin --replace --xml-file tmp.xml
cibadmin是用于操作 Heartbeat CIB 的低级管理命令。它可以用来转储、更新或修改所有或部分 CIB,删除整个 CIB 或执行各种 CIB 管理操作。
集群配置信息是Pacemaker集群中CIB信息的关键组成部分,Pacemaker的集群配置信息决定了集群最终应该如何工作以及集群最终的运行状态,因为只有一个正确的集群配置才能驱动集群资源运行在正常的状态。通常情况下,集群的配置信息由集群配置选项(crm_config)、集群节点(nodes)、集群资源(resources)和资源约束(constraints)四个配置段组成,通过 cibadmin --query可查。
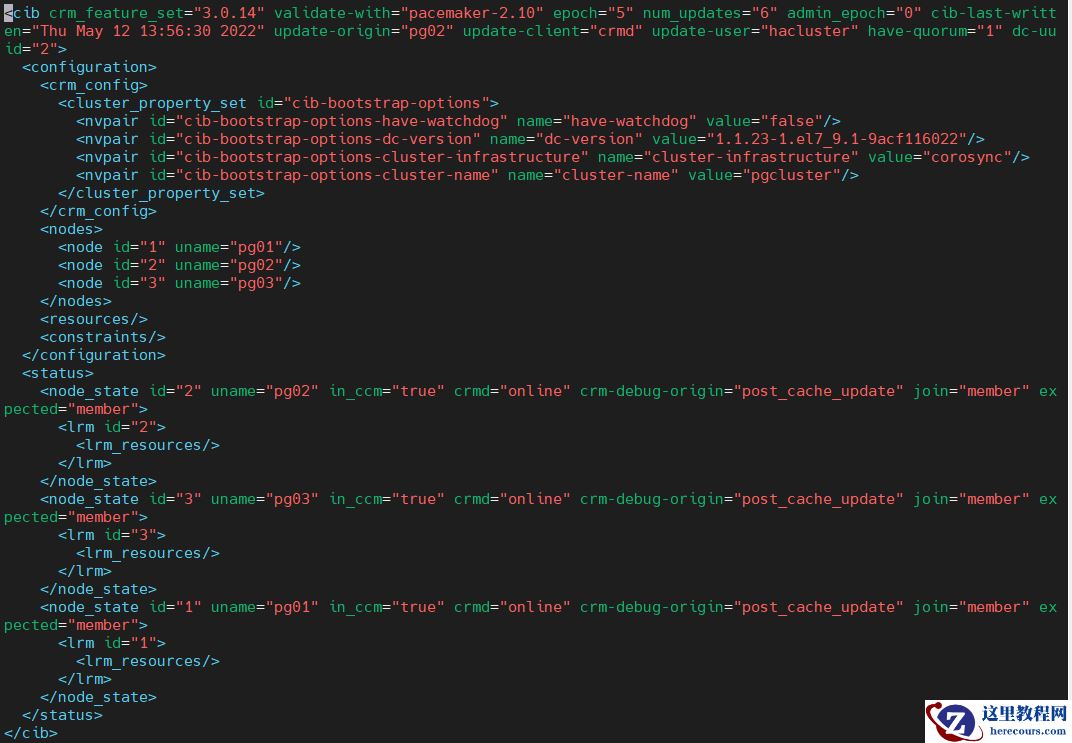
六、集群状态检查
1.启动集群并设置开机自启动
数据库无需配置自启动,由集群软件自动拉起
pcs cluster start --all
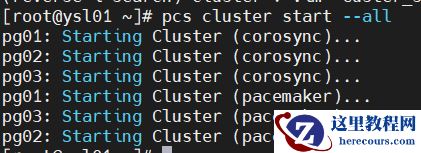
pcs cluster enable --all

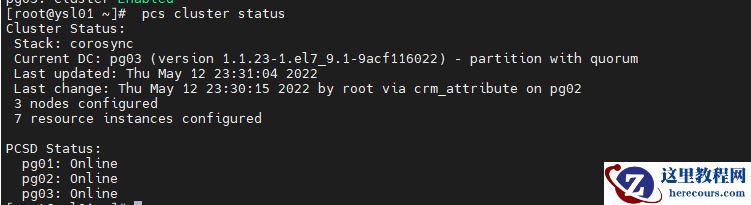
2.查看集群状态
pcs cluster status
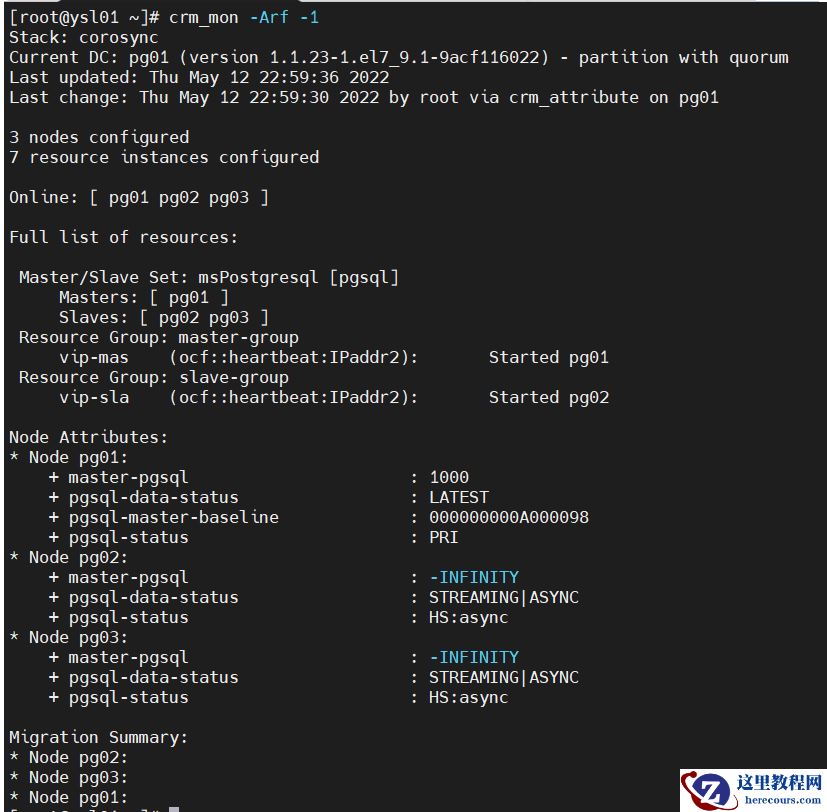
3、查看本机集群状态及资源状态
crm_mon -Afr -1
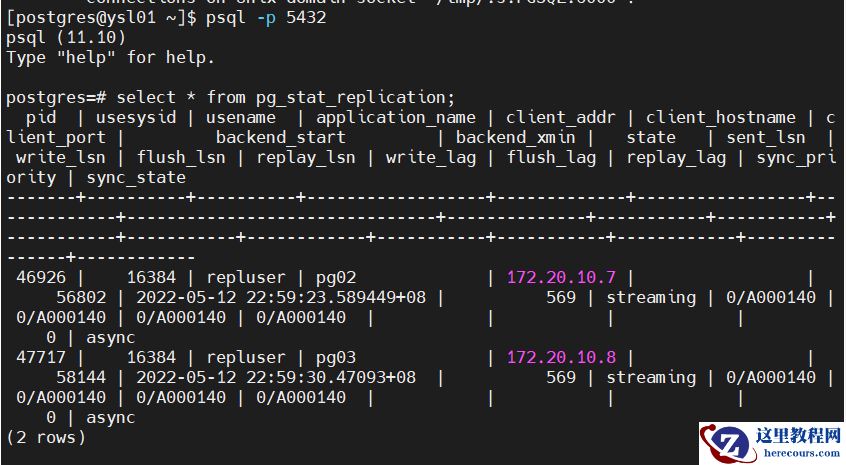
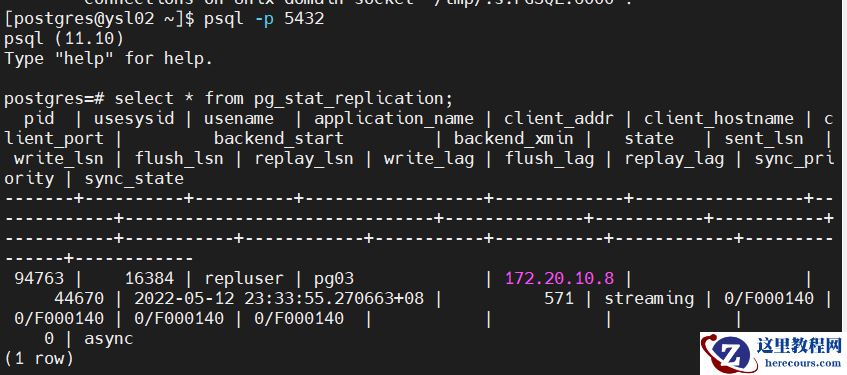
4.查看主节点流复制状态
select * from pg_stat_replication;
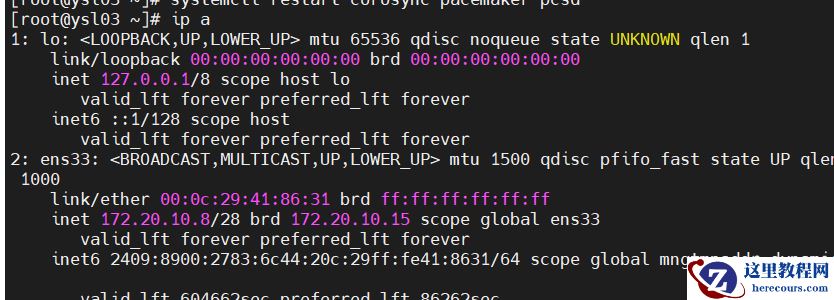
5.查看vip挂载情况
节点1
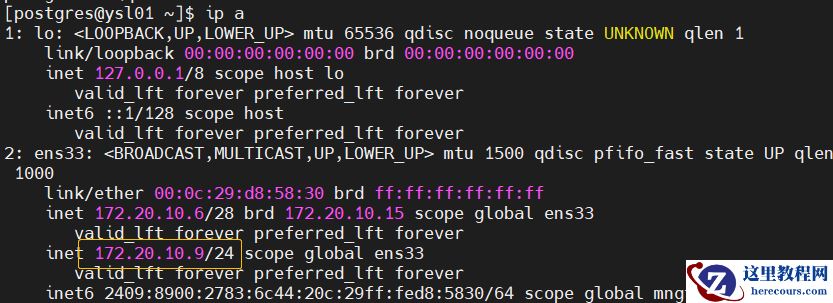 节点2
节点2
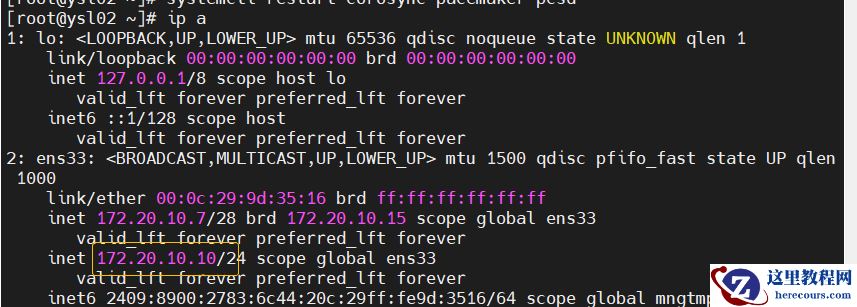 节点3
节点3
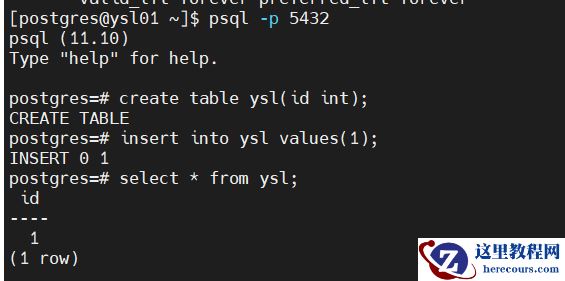
七、数据同步验证
主节点插入数据
postgres=# create table ysl(id int); CREATE TABLE postgres=# insert into ysl values(1); INSERT 0 1 postgres=# select * from ysl; id ---- 1 (1 row)
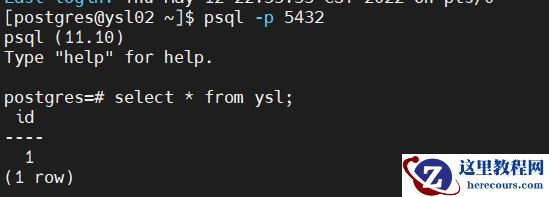
 备机查看
备机查看
八、故障模拟
停掉主库,节点2提升为主节点
pg_ctl stop
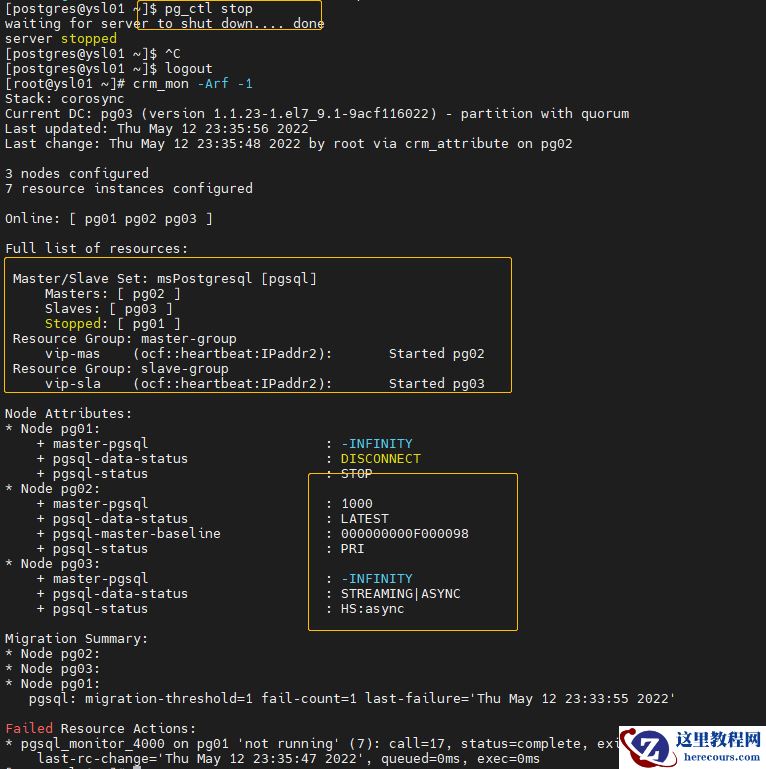
节点3成为节点2的备机
注意master节点挂掉之后,使用 crm_mon -Arf -1命令看到末尾有"
You have to remove /var/lib/pgsql/tmp/PGSQL.lock file to force start."字样,master宕机启动时,需要删除临时锁文件方可进行集群角色转换。即执行
rm -rf /var/lib/pgsql/tmp/PGSQL.lock

拉起数据库不需要执行pg_ctl start,只需重启服务,软件会自动把数据库拉起。
systemctl restart corosync pacemaker pcsd
九、集群常用操作
pcs status //查看集群状态 pcs resource show //查看资源 pcs resource create ClusterIP IPaddr2 ip=192.168.0.120 cidr_netmask=32 //创建一个虚拟IP资源 pcs resource cleanup //xx表示虚拟资源名称,当集群有资源处于unmanaged的状态时,可以用这个命令清理掉失败的信息,然后重置资源状态 pcs resource list //查看资源列表 pcs resource restart //重启资源 pcs resource enable //启动资源 pcs resource disable //关闭资源 pcs resource delete //删除资源 crm_mon -Arf -1 //查看同步状态和资源







")



