Oracle 面试宝典 - 表连接篇


 请问在Oracle
数据库多表连接时,优化器在生成执行计划时需要考虑哪些因素?
优化器会预估出不同的
访问路径
(
如何从每张表里取数据,全表扫描还是索引扫描
)
、
连接方式
(
每个表之间如何连接,
Nested Loops
、
Hash Join
、
Sort Merge)
、
连接类型
、
连接顺序
下获取最终结果消耗的成本值,并选择预估
成本最低
的执行计划。
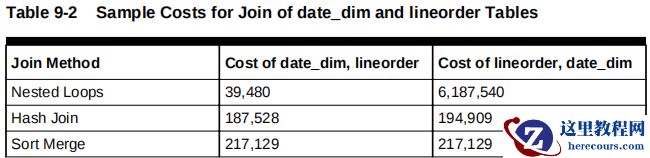
例如:date_dim
和
lineorder
表进行连接,优化器会计算出不同连接方式
(Nested Loops join
、
Hash Join
、
Sort Merge join)
,不同连接顺序
(date_dim,lineorder
或
lineorder,date_dim)
下
costs
值,在本例中
Nested Loops
连接方式
,date_dim,lineorder
连接顺序的成本最低。
请问在Oracle
数据库多表连接时,优化器在生成执行计划时需要考虑哪些因素?
优化器会预估出不同的
访问路径
(
如何从每张表里取数据,全表扫描还是索引扫描
)
、
连接方式
(
每个表之间如何连接,
Nested Loops
、
Hash Join
、
Sort Merge)
、
连接类型
、
连接顺序
下获取最终结果消耗的成本值,并选择预估
成本最低
的执行计划。
例如:date_dim
和
lineorder
表进行连接,优化器会计算出不同连接方式
(Nested Loops join
、
Hash Join
、
Sort Merge join)
,不同连接顺序
(date_dim,lineorder
或
lineorder,date_dim)
下
costs
值,在本例中
Nested Loops
连接方式
,date_dim,lineorder
连接顺序的成本最低。
 请问有哪些访问路径?
一:Table Access Paths
Direct Path Reads
Full Table Scans
Table Access by Rowid
In-Memory Table Scans
二:B-Tree Index Access Paths
Index Unique Scans
Index Range Scans
Index Full Scans
Index Fast Full Scans
Index Skip Scans
Index Join Scans
三:Bitmap Index Access Paths
Bitmap Conversion to Rowid
Bitmap Index Single Value
Bitmap Index Range Scans
Bitmap Merge
四:Table Cluster Access Paths
Cluster Scans
Hash Scans
请问连接类型有哪些?
Inner Joins
、
Outer Joins
、
Semijoins
、
Antijoins
、
Cartesian Joins
请问有哪些常见连接方式,有什么区别,分别适用哪些场景?
连接方式有:
嵌套循环连接(Nested Loops Joins)
、
哈希连接(Hash Joins)
、
排序合并连接(Sort Merge Joins)
嵌套循环连接(Nested Loops Joins)
:
原理:
两个表在连接时,通过两层嵌套for
循环进行依次匹配,最终返回结果集。
1
首先
oracle
选择驱动表
T1(
外部表
)
和被驱动表
T2(
内部表
)
,通常结果集小的表选做驱动表。
2
根据谓词条件,查询驱动表得到结果集
A1
。
3
从驱动表结果集
A1
中取出一条数据,按照驱动表
T1
和被驱动表
T2
关联条件查看是否有匹配的数据,
能够匹配则保留,
不能匹配则忽略此行
,
然后再从
A
1
中取出下一条记录
,
接着遍历
T2
进行匹配
,
如此下去直到取完
A
1
中的所有记录
。
适用场景:
1.
小结果集连接
2.
驱动表结果集很小
(
小表或者通过谓词过滤后结果集小的表
)
3.
驱动表的谓词连接列和被驱动表的谓词连接列上有高效索引
4.
不必等待处理完成所有行前可以先返回部分已经处理完成的数据
5.
支持等值连接和非等值连接。
案例:
SELECT
/*+ ORDERED USE_NL(d) */
e.last_name
,
e.first_name
,
d.department_name
FROM
employees e
,
departments d
WHERE
e.department_id
=
d.department_id
AND
e.last_name
like
'A%'
;
过程大致如下:
请问有哪些访问路径?
一:Table Access Paths
Direct Path Reads
Full Table Scans
Table Access by Rowid
In-Memory Table Scans
二:B-Tree Index Access Paths
Index Unique Scans
Index Range Scans
Index Full Scans
Index Fast Full Scans
Index Skip Scans
Index Join Scans
三:Bitmap Index Access Paths
Bitmap Conversion to Rowid
Bitmap Index Single Value
Bitmap Index Range Scans
Bitmap Merge
四:Table Cluster Access Paths
Cluster Scans
Hash Scans
请问连接类型有哪些?
Inner Joins
、
Outer Joins
、
Semijoins
、
Antijoins
、
Cartesian Joins
请问有哪些常见连接方式,有什么区别,分别适用哪些场景?
连接方式有:
嵌套循环连接(Nested Loops Joins)
、
哈希连接(Hash Joins)
、
排序合并连接(Sort Merge Joins)
嵌套循环连接(Nested Loops Joins)
:
原理:
两个表在连接时,通过两层嵌套for
循环进行依次匹配,最终返回结果集。
1
首先
oracle
选择驱动表
T1(
外部表
)
和被驱动表
T2(
内部表
)
,通常结果集小的表选做驱动表。
2
根据谓词条件,查询驱动表得到结果集
A1
。
3
从驱动表结果集
A1
中取出一条数据,按照驱动表
T1
和被驱动表
T2
关联条件查看是否有匹配的数据,
能够匹配则保留,
不能匹配则忽略此行
,
然后再从
A
1
中取出下一条记录
,
接着遍历
T2
进行匹配
,
如此下去直到取完
A
1
中的所有记录
。
适用场景:
1.
小结果集连接
2.
驱动表结果集很小
(
小表或者通过谓词过滤后结果集小的表
)
3.
驱动表的谓词连接列和被驱动表的谓词连接列上有高效索引
4.
不必等待处理完成所有行前可以先返回部分已经处理完成的数据
5.
支持等值连接和非等值连接。
案例:
SELECT
/*+ ORDERED USE_NL(d) */
e.last_name
,
e.first_name
,
d.department_name
FROM
employees e
,
departments d
WHERE
e.department_id
=
d.department_id
AND
e.last_name
like
'A%'
;
过程大致如下:
 (1)
首先
oracle
会根据一定的规则
(
根据统计信息的成本计算或者
hint
强制
)
决定哪个表是驱动表
,
哪个表是被驱动表
,看执行计划可知,驱动表示employees,
因为外部循环出现在执
行计划的内部循环之前,例如:
NESTED LOOPS
outer_loop
inner_loop
(2)
查询驱动表
"select * from employees where last_name like 'A%'"
然后得到驱动结果集
Q1
(3)
遍历驱动结果集
Q1
以及被驱动表
departments
,
从驱动结果集
Q1
中取出一条记录
,
接着遍历
departments
并按照连接条件
departments
.
department_id
=
employees
.
department_id
去判断
departments
中是否存在匹配的记录,
如果能够匹配则保留
,
不能匹配则忽略此行
,
然后再从
Q1
中取出下一条记录
,
接着遍历
departments
进行匹配,
如此下去直到取完
Q1
中的所有记录
。
查看执行计划:
(1)
首先
oracle
会根据一定的规则
(
根据统计信息的成本计算或者
hint
强制
)
决定哪个表是驱动表
,
哪个表是被驱动表
,看执行计划可知,驱动表示employees,
因为外部循环出现在执
行计划的内部循环之前,例如:
NESTED LOOPS
outer_loop
inner_loop
(2)
查询驱动表
"select * from employees where last_name like 'A%'"
然后得到驱动结果集
Q1
(3)
遍历驱动结果集
Q1
以及被驱动表
departments
,
从驱动结果集
Q1
中取出一条记录
,
接着遍历
departments
并按照连接条件
departments
.
department_id
=
employees
.
department_id
去判断
departments
中是否存在匹配的记录,
如果能够匹配则保留
,
不能匹配则忽略此行
,
然后再从
Q1
中取出下一条记录
,
接着遍历
departments
进行匹配,
如此下去直到取完
Q1
中的所有记录
。
查看执行计划:
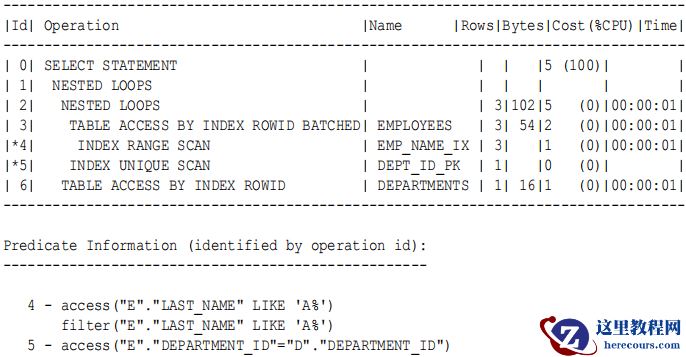 执行计划解读:
1.
根据谓词
e.last_name like 'A%'
,在
employees
表
last_name
字段上索引
emp_name_ix
中搜索对应
last_name
的值和
rowid
,查找
A
开头的所有
last_name
数据,对应执行计划第4
步。
例如搜索到如下数据:
Abel,employees_rowid
Ande,employees_rowid
Atkinson,employees_rowid
...
2.
通过上一步的
employees_rowid
,回表获取
employees
表
上其他字段的值(first_name
,
department_id),
对应执行计划第
3
步。
Abel,Ellen,80
Abel,John,50
...
3.
对于外部行源中的每一行,数据库扫描
departments
表
department_id
字段上主键索引
dept_id_pk
以获得匹配索引中
department_id
对应的
rowid(
执行计划第
5
步
)
, 并将其连接到
employees
行。例如:
Abel,Ellen,80,departments_rowid
Ande,Sundar,80,departments_rowid
Atkinson,Mozhe,50,departments_rowid
...
4.
通过上一步的
departments_rowid
,回表获取
departments
表上其他字段的值
(department_name,department_id)
,对应执行计划第
6
步。
5.
通过
departments
表
department_id
值和
employees
表department_id
值获取需要的字段
(
对应执行计划第
1
步
)
,
employees
.last_name,
employees
.first_name,department_id,departments.department_name
例如:
Abel,Ellen,80,Sales
6.
读取外部行源中的下一行,使用
departments rowid
从
departments
检索相应的行(步骤
6
),并遍历循环,直到检索到所有行。
结果集的格式如下:
Abel,Ellen,80,Sales
Ande,Sundar,80,Sales
Atkinson,Mozhe,50,Shipping
...
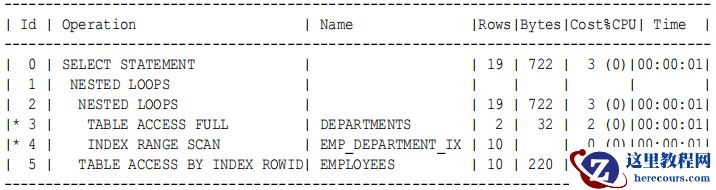
11g Nested Loop Join的改变
:
11g
开始的执行计划
执行计划解读:
1.
根据谓词
e.last_name like 'A%'
,在
employees
表
last_name
字段上索引
emp_name_ix
中搜索对应
last_name
的值和
rowid
,查找
A
开头的所有
last_name
数据,对应执行计划第4
步。
例如搜索到如下数据:
Abel,employees_rowid
Ande,employees_rowid
Atkinson,employees_rowid
...
2.
通过上一步的
employees_rowid
,回表获取
employees
表
上其他字段的值(first_name
,
department_id),
对应执行计划第
3
步。
Abel,Ellen,80
Abel,John,50
...
3.
对于外部行源中的每一行,数据库扫描
departments
表
department_id
字段上主键索引
dept_id_pk
以获得匹配索引中
department_id
对应的
rowid(
执行计划第
5
步
)
, 并将其连接到
employees
行。例如:
Abel,Ellen,80,departments_rowid
Ande,Sundar,80,departments_rowid
Atkinson,Mozhe,50,departments_rowid
...
4.
通过上一步的
departments_rowid
,回表获取
departments
表上其他字段的值
(department_name,department_id)
,对应执行计划第
6
步。
5.
通过
departments
表
department_id
值和
employees
表department_id
值获取需要的字段
(
对应执行计划第
1
步
)
,
employees
.last_name,
employees
.first_name,department_id,departments.department_name
例如:
Abel,Ellen,80,Sales
6.
读取外部行源中的下一行,使用
departments rowid
从
departments
检索相应的行(步骤
6
),并遍历循环,直到检索到所有行。
结果集的格式如下:
Abel,Ellen,80,Sales
Ande,Sundar,80,Sales
Atkinson,Mozhe,50,Shipping
...
11g Nested Loop Join的改变
:
11g
开始的执行计划
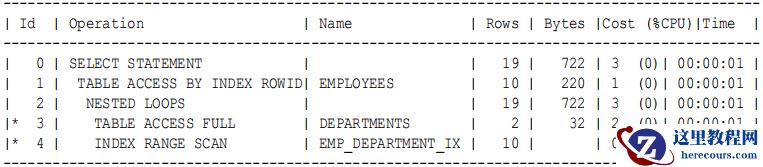
 11g
之前的执行计划
11g
之前的执行计划
 https://blogs.oracle.com/database4cn/11g-nested-loop-join
Oracle 11g
关于
Nested Loop Join
的改变,并不在
Join
顺序或者中间结果集的存放方法上,而仅仅是在操作系统函数调用上封装了一层,把以前依次提交的多个
I/O
请求封装到了一个结构体中,并一次提交这些请求。
比较与线性I/O
的实现,向量
I/O
的实现除了可以减少系统调用的次数,还可以经内部的优化提供性能的改善。
哈希连接(Hash Joins)
http://www.dbsnake.net/oracle-hash-join.html
https://blogs.oracle.com/database4cn/11g-nested-loop-join
Oracle 11g
关于
Nested Loop Join
的改变,并不在
Join
顺序或者中间结果集的存放方法上,而仅仅是在操作系统函数调用上封装了一层,把以前依次提交的多个
I/O
请求封装到了一个结构体中,并一次提交这些请求。
比较与线性I/O
的实现,向量
I/O
的实现除了可以减少系统调用的次数,还可以经内部的优化提供性能的改善。
哈希连接(Hash Joins)
http://www.dbsnake.net/oracle-hash-join.html
在Oracle 7.3 之前, Oracle 数据库中的常用表连接方法就只有排序合并连接和嵌套循环连接这两种,但这两种表连接方法都有其明显缺陷。对于排序合并连接,如果两个表在施加了目标 SQL 中指定的谓词条件(如果有的话)后得到的结果集很大且需要排序的话,则这种情况下的排序合并连接的执行效率一定是很差的;而对于嵌套循环连接,如果驱动表所对应的驱动结果集的记录数很大,即便在被驱动表的连接列上存在索引,此时使用嵌套循环连接的执行效率也同样会很差。
为了解决排序合并连接和嵌套循环连接在上述情形下执行效率不高的问题,同时也为了给优化器提供一种新的选择,
Oracle
在
Oracle 7.3
中引入了哈希连接。从理论上来说,哈希连接的执行效率会比排序合并连接和嵌套循环连接的执行效率要高,当然,实际情况并不总是这样。
原理:
做表连接时主要依靠哈希运算来得到连接结果集的表连接方法。
1.
首先
oracle
选择驱动表
T1(
内部表
[
用于构建
hash
表
])
和被驱动表
T2(
外部表
[
探测表
])
,通常
表
T1
和
T2
在施加了目标
SQL
中指定的谓词条件(如果有的话)后得到的结果集中数据量较小的那个结果集被
Oracle
选为哈希连接的驱动结果集
。
这里我们假设
T1
所对应的结果集的数据量相对较小,我们记为
S
;
T2
所对应的结果集的数据量相对较大,我们记为
B
;显然这里
S
是驱动结果集,
B
是被驱动结果集;
2.
根据驱动表,建立一个可以存在于
PGA
内存中
hash area
区域的
hash table
。
 3.
然后用大的结果集
B
来探测前面所建的
hash table
。每读取大表的一条记录,就和小表中内存中的数据进行比较,如果符合,则立即输出数据(也就是说没有读取临时表空间中的小表的数据)。而如果大表的数据与小表中临时表空间的数据相符合,则不直接输出,而是也被存储临时表空间中。
3.
然后用大的结果集
B
来探测前面所建的
hash table
。每读取大表的一条记录,就和小表中内存中的数据进行比较,如果符合,则立即输出数据(也就是说没有读取临时表空间中的小表的数据)。而如果大表的数据与小表中临时表空间的数据相符合,则不直接输出,而是也被存储临时表空间中。
 适用场景:
1
相对于
nested loop,
哈希连接更适合较大的数据集。
2
哈希连接只适用于
CBO
、只能用于等值连接条件。
3
当两个表做哈希连接时,如果这两个表在施加了目标
SQL
中指定的谓词条件(如果有的话)后得到的结果集中数据量较小的那个结果集所对应的
Hash Table
能够完全被容纳在内存中时(
PGA
的工作区),则此时的哈希连接的执行效率会非常高。
4
哈希连接很适合于一个小表和大表之间的表连接,特别是在小表的连接列的可选择性非常好的情况下,这时候哈希连接的执行时间就可以近似看作是和全表扫描那个大表所耗费的时间相当;
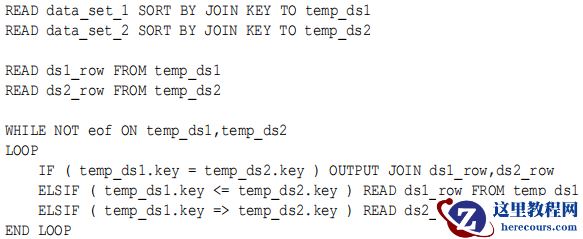
排序合并连接(Sort Merge Joins)
原理:
https://www.cnblogs.com/elontian/p/9483329.html
指的是两个表连接时,
通过连接列先分别排序后
,
再通过合并操作来得到最终结果集的方法。
假如表T1
和
T2
的连接方式是排序合并连接
, oracle
执行步骤如下
:
(1)
根据
sql
语句中的谓词条件
(
如果有
)
访问
T1
表
,
得到一个过滤的结果集
,
然后按照
T1
中的连接列对结果集进行排序
(2)
根据
sql
语句中的谓词条件
(
如果有
)
访问
T2
表
,
得到一个过滤的结果集
,
然后按照
T2
中的连接列对结果集进行排序
(3)
将
1
和
2
的结果集合并起来
,
对记录进行匹配得到最后的结果集
.
适用场景:
1
相对于
nested loop,
哈希连接更适合较大的数据集。
2
哈希连接只适用于
CBO
、只能用于等值连接条件。
3
当两个表做哈希连接时,如果这两个表在施加了目标
SQL
中指定的谓词条件(如果有的话)后得到的结果集中数据量较小的那个结果集所对应的
Hash Table
能够完全被容纳在内存中时(
PGA
的工作区),则此时的哈希连接的执行效率会非常高。
4
哈希连接很适合于一个小表和大表之间的表连接,特别是在小表的连接列的可选择性非常好的情况下,这时候哈希连接的执行时间就可以近似看作是和全表扫描那个大表所耗费的时间相当;
排序合并连接(Sort Merge Joins)
原理:
https://www.cnblogs.com/elontian/p/9483329.html
指的是两个表连接时,
通过连接列先分别排序后
,
再通过合并操作来得到最终结果集的方法。
假如表T1
和
T2
的连接方式是排序合并连接
, oracle
执行步骤如下
:
(1)
根据
sql
语句中的谓词条件
(
如果有
)
访问
T1
表
,
得到一个过滤的结果集
,
然后按照
T1
中的连接列对结果集进行排序
(2)
根据
sql
语句中的谓词条件
(
如果有
)
访问
T2
表
,
得到一个过滤的结果集
,
然后按照
T2
中的连接列对结果集进行排序
(3)
将
1
和
2
的结果集合并起来
,
对记录进行匹配得到最后的结果集
.
 适用场景:
1.
当结果集已经排过序
(
例如:索引
)
。
2.
由于
hash joins
只能用于等值连接条件
,
所以在非等值条件连接情况下
,
如果连接列上已经有排序
,
使用
sort merge joins
连接方式也能获得比较好的执行效率。
欢迎关注我的微信公众号"IT小Chen",共同学习,共同成长!!!
适用场景:
1.
当结果集已经排过序
(
例如:索引
)
。
2.
由于
hash joins
只能用于等值连接条件
,
所以在非等值条件连接情况下
,
如果连接列上已经有排序
,
使用
sort merge joins
连接方式也能获得比较好的执行效率。
欢迎关注我的微信公众号"IT小Chen",共同学习,共同成长!!!






_概念介绍")





")