问题现象:
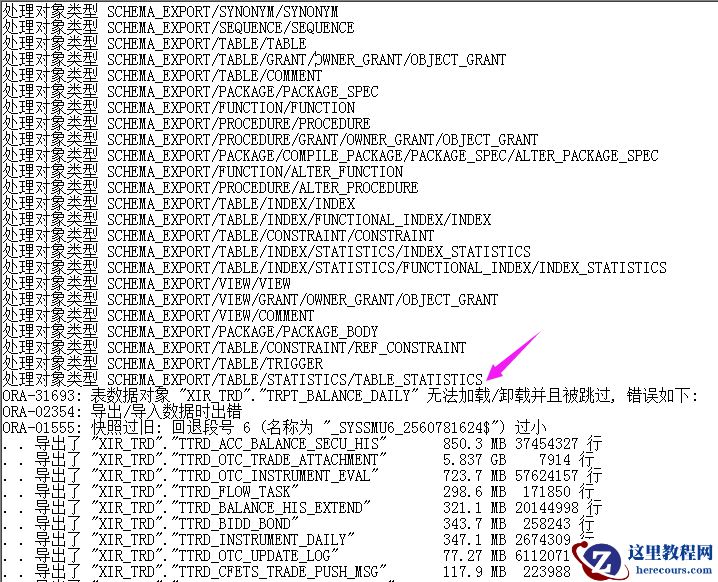 解决过程Level1:1. 出现ORA-01555错误,通常有2种情况:(1)SQL语句执行时间太长,或者UNDO表空间过小,或者事务量过大,或者过于频繁的提交,导致执行SQL过程中进行一致性读时,SQL执行后修改的前镜像(即UNDO数据)在UNDO表空间中已经被覆盖,不能构造一致性读块(CR
blocks)。 这种情况最多。(2)SQL语句执行过程中,访问到的块,在进行延迟块清除时,不能确定该块的事务提交时间与SQL执行开始时间的先后次序。 这种情况很少。2. 第1种情况解决的办法:(1)增加UNDO表空间大小(2)增加undo_retention 时间,默认只有15分钟数据库undo表空间使用率极低,将undo_retention由默认的900秒调整到5400秒,报错解决。解决过程Level2: 一张不到10G的表,导出耗时了一小时还多,肯定是有异常的,决定深挖这个问题。执行了单表数据泵导出,发现耗时为1小时(多次执行误差在5分钟内),执行以下sql进行具体分析:select count(*),avg(time_waited)/1000,event,program,blocking_session from v$active_session_history where sample_time between to_date('2021-02-19 08:30','yyyy-mm-dd hh24:mi) and to_date('2021-02-19 09:45','yyyy-mm-dd hh24:mi) and blocking_session is not null group by event,program order by 2
解决过程Level1:1. 出现ORA-01555错误,通常有2种情况:(1)SQL语句执行时间太长,或者UNDO表空间过小,或者事务量过大,或者过于频繁的提交,导致执行SQL过程中进行一致性读时,SQL执行后修改的前镜像(即UNDO数据)在UNDO表空间中已经被覆盖,不能构造一致性读块(CR
blocks)。 这种情况最多。(2)SQL语句执行过程中,访问到的块,在进行延迟块清除时,不能确定该块的事务提交时间与SQL执行开始时间的先后次序。 这种情况很少。2. 第1种情况解决的办法:(1)增加UNDO表空间大小(2)增加undo_retention 时间,默认只有15分钟数据库undo表空间使用率极低,将undo_retention由默认的900秒调整到5400秒,报错解决。解决过程Level2: 一张不到10G的表,导出耗时了一小时还多,肯定是有异常的,决定深挖这个问题。执行了单表数据泵导出,发现耗时为1小时(多次执行误差在5分钟内),执行以下sql进行具体分析:select count(*),avg(time_waited)/1000,event,program,blocking_session from v$active_session_history where sample_time between to_date('2021-02-19 08:30','yyyy-mm-dd hh24:mi) and to_date('2021-02-19 09:45','yyyy-mm-dd hh24:mi) and blocking_session is not null group by event,program order by 2
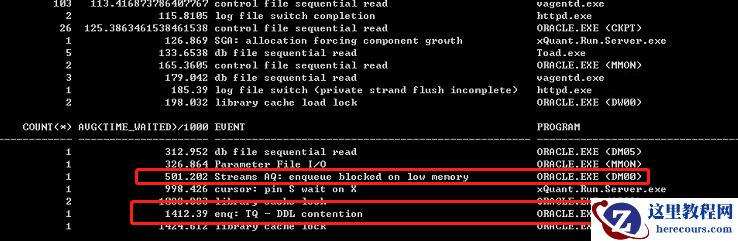 发现事件里面有报内存不足,遂调整stream pool大小,由64m增加到128m,再次执行单表数据泵导出,发现耗时减少至50分钟左右。解决过程Level3: 一张不到10G的表,导出耗时近1一小时,肯定依旧存在问题,继续挖!目标转移至系统备库,测试同样的表导出耗时,不测不知道一测吓一跳,相同性能相同数据量的备库,同样的表导出只用了5分钟,主备库差异主要为主库运行着系统程序,备库什么程序都没跑,遂找到窗口期将主库所有连库程序停掉,再次测试,发现耗时缩短至40分钟,有改善,但根源问题依旧没有解决!解决过程Level4: 分析主备库AWR报告,发现执行数据泵导出时段,性能差异主要区别在IO上,主库比备库多出了太多的IO读写操作,好了,此刻似乎可以帅锅给操作系统了,硬件问题、操作系统安装问题、操作系统配置问题……总之就是跟我数据库没有关系了。解决过程Level5: 本着根源挖到底的原则,继续查阅资料,发现有如下概念会影响IO:行迁移(参考链接:
https://blog.csdn.net/hotye393/article/details/6226471)
主备库依次执行以下操作:@/home/oracle/product/11.2.0/rdbms/admin/utlchain.sqlanalyze table ***.************ list chained rows;比对结果数量:select count(*) from chained_rows,最终发现根源原因,主库比备库多出了近十倍的行迁移!!!问题根源找到了,解决方法就水到渠成了:
发现事件里面有报内存不足,遂调整stream pool大小,由64m增加到128m,再次执行单表数据泵导出,发现耗时减少至50分钟左右。解决过程Level3: 一张不到10G的表,导出耗时近1一小时,肯定依旧存在问题,继续挖!目标转移至系统备库,测试同样的表导出耗时,不测不知道一测吓一跳,相同性能相同数据量的备库,同样的表导出只用了5分钟,主备库差异主要为主库运行着系统程序,备库什么程序都没跑,遂找到窗口期将主库所有连库程序停掉,再次测试,发现耗时缩短至40分钟,有改善,但根源问题依旧没有解决!解决过程Level4: 分析主备库AWR报告,发现执行数据泵导出时段,性能差异主要区别在IO上,主库比备库多出了太多的IO读写操作,好了,此刻似乎可以帅锅给操作系统了,硬件问题、操作系统安装问题、操作系统配置问题……总之就是跟我数据库没有关系了。解决过程Level5: 本着根源挖到底的原则,继续查阅资料,发现有如下概念会影响IO:行迁移(参考链接:
https://blog.csdn.net/hotye393/article/details/6226471)
主备库依次执行以下操作:@/home/oracle/product/11.2.0/rdbms/admin/utlchain.sqlanalyze table ***.************ list chained rows;比对结果数量:select count(*) from chained_rows,最终发现根源原因,主库比备库多出了近十倍的行迁移!!!问题根源找到了,解决方法就水到渠成了:
alter table ***.******** move nologging parallel 4;
alter table ***.******** logging noparallel;
select index_name from dba_indexes where table_name='*******';
alter index ***.******** rebuild;
表导出耗时2分钟,已超越备库,至此问题得到彻底解决!






索引片和匹配列概述")


Grid软件安装")


