本文整理自 IvorySQL 2025 生态大会暨 PostgreSQL 高峰论坛的演讲分享,演讲嘉宾:孟飞龙,瀚高股份研发工程师。
本文主要从以下 4 个方面进行分享:
前言
前言部分主要介绍一些 PostgreSQL 高可用相关的概念,让大家对高可用有一个大概的了解。
PostgreSQL 高可用简述
高可用的作用 在数据库宕机的危机时刻,PostgreSQL 高可用架构会通过一系列精密设计的机制,悄然接管服务并保障业务连续性。
高可用的基础 流复制,主库将预写日志(WAL)实时发送至备库,备库通过应用日志实现数据同步。同步复制模式下牺牲部分性能换取零数据丢失。
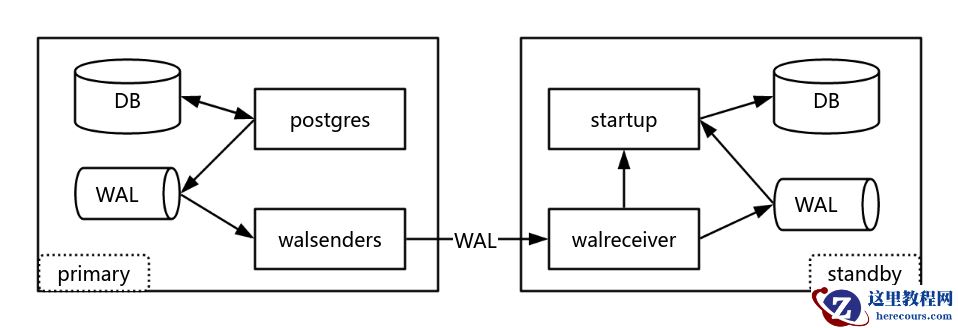
上图为流复制示意图。左侧为主库,当用户写入数据,数据库不会直接把数据写入磁盘,而是先把 WAL 写到磁盘,然后通过 walsenders 进程将 WAL 发送到备库。右侧的备库,通过 walreceiver 进程接收 WAL 日志,然后通过 startup 进程将日志进行重做,使数据落盘,从而实现主备之间的数据同步。为了实现数据的零丢失,一般会将流复制模式设置为同步模式。
高可用的动作 提升备库为新主库,通常通过设置 vip 使应用无感知地连接主库。
高可用的难题 脑裂防护,如因网络分区造成的多主问题。
PostgreSQL 高可用开源软件
故障检测与转移
故障检测
1. 数据库故障检测
高可用组件通过检查主库进程状态或数据库连接来判断健康状况:
工作原理:
2. 服务器故障检测
高可用组件通过主库状态判断健康状况:
工作原理:
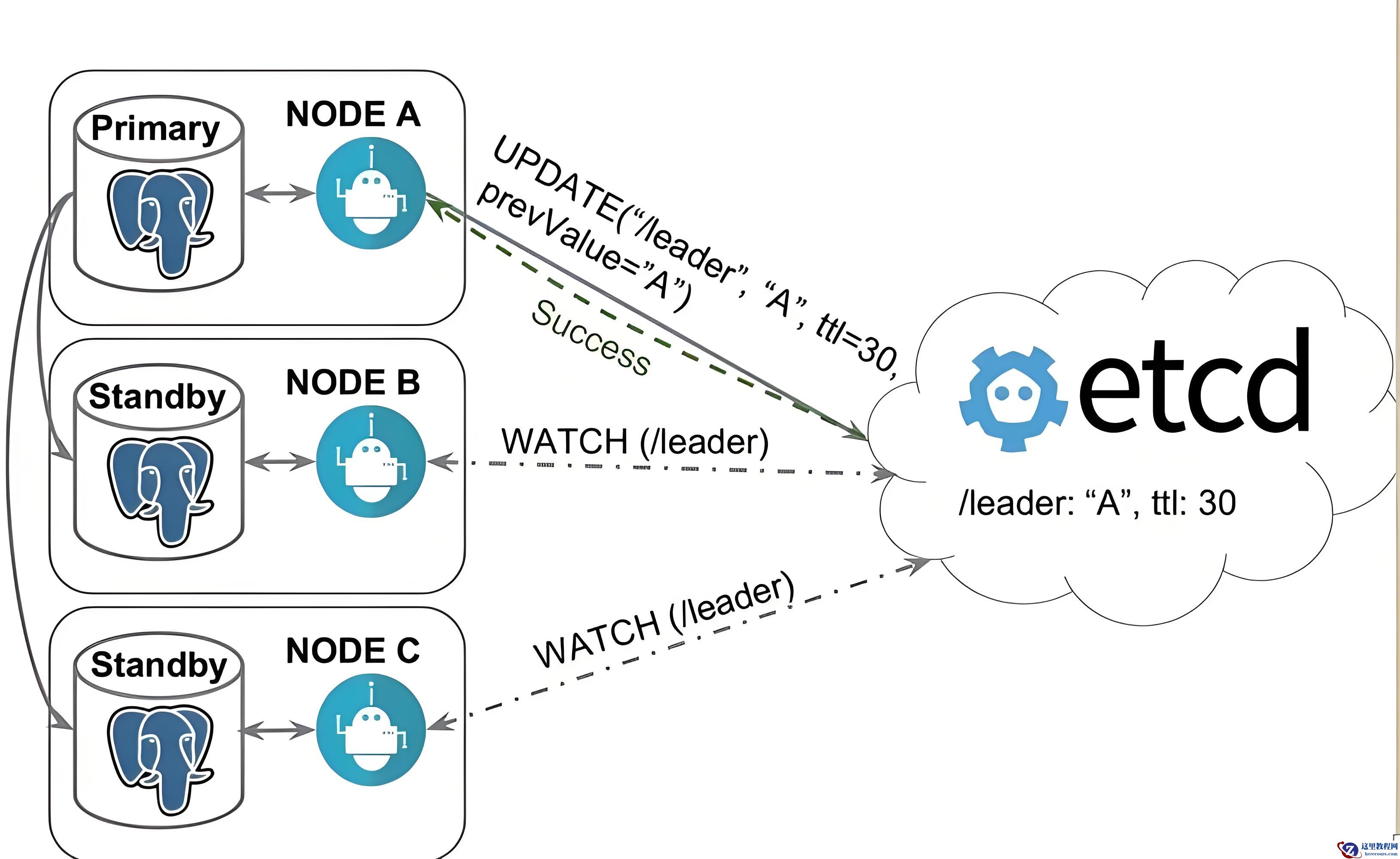
故障转移
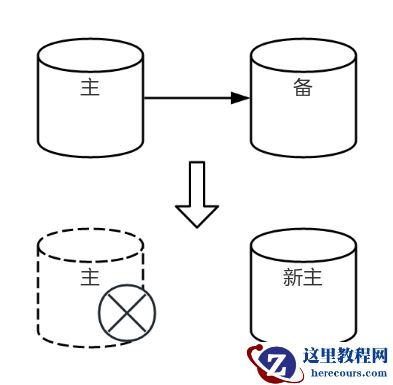
当主库故障且高可用软件判断无法恢复时,需选举新主节点并执行 promote 操作以恢复服务。由于通常配置多个备节点(Node B),需通过选举确定哪一节点成为新主。
问题探讨
RPO 和 RTO
-
RPO 与性能
RPO(Recovery Point Objective,恢复点目标) 是衡量系统在故障或灾难发生后,允许丢失的数据量(以时间为单位)——数据丢多少。
想要做到 RPO=0 需要将流复制设置为同步模式,备库延迟过高会影响主库的写入。
-
RTO 与稳定
RTO(Recovery Time Objective,恢复时间目标)是衡量系统在故障或灾难发生后,业务功能恢复到可接受水平所需的最大可接受时间——多久能恢复。
想要减小 RTO 就需要减小高可用的检测间隔,但较小的检测间隔又会影响集群的稳定,一点网络波动就会造成误判,导致集群频频切换主备。
离线节点回归
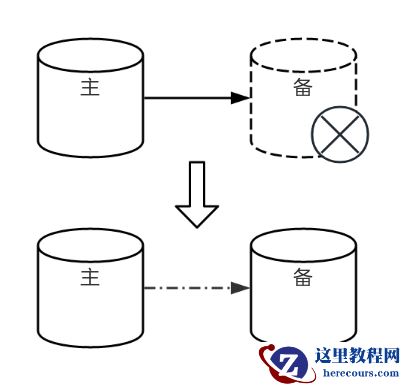
问题描述
长时间离线节点回归集群时,因缺失 WAL(Write Ahead Log)日志,无法与主库建立流复制。
解决方法
-
配置物理复制槽
- 优点:可支持节点回归。
- 缺点:配置复杂,且若节点yongjiu离线,主库物理复制槽保留 WAL 日志,占用磁盘空间。
-
配置日志归档与恢复
- 方法:将 WAL 日志备份至远程磁盘,确保离线节点回归后可恢复。
- 缺点:需额外远程服务器资源。
-
无配置时的应急方法
- 方法:重做备库(最原始方式)。
注意事项
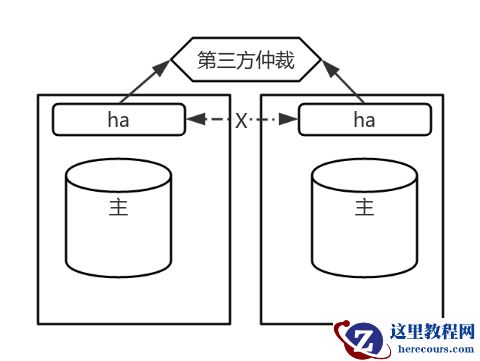
脑裂防护
问题描述
数据库脑裂会导致应用无法判断数据写入目标主库,引发数据分歧或丢失。
解决方法
- Watchdog:若长时间未接收 Patroni 心跳,触发系统重启。
- 故障重启:故障重启:通过 systemd 服务配置 Patroni 故障重启机制。
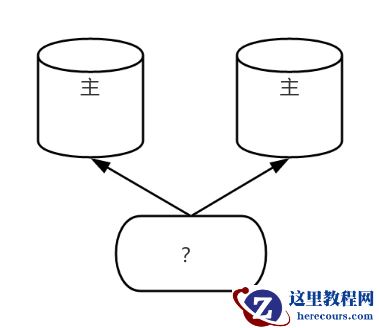
两节点部署的极限问题
问题背景
通常,稳定的 PG 高可用集群需至少三个节点支持。但客户仅提供两台服务器,需实现高可用。
解决方法
风险与局限
结语
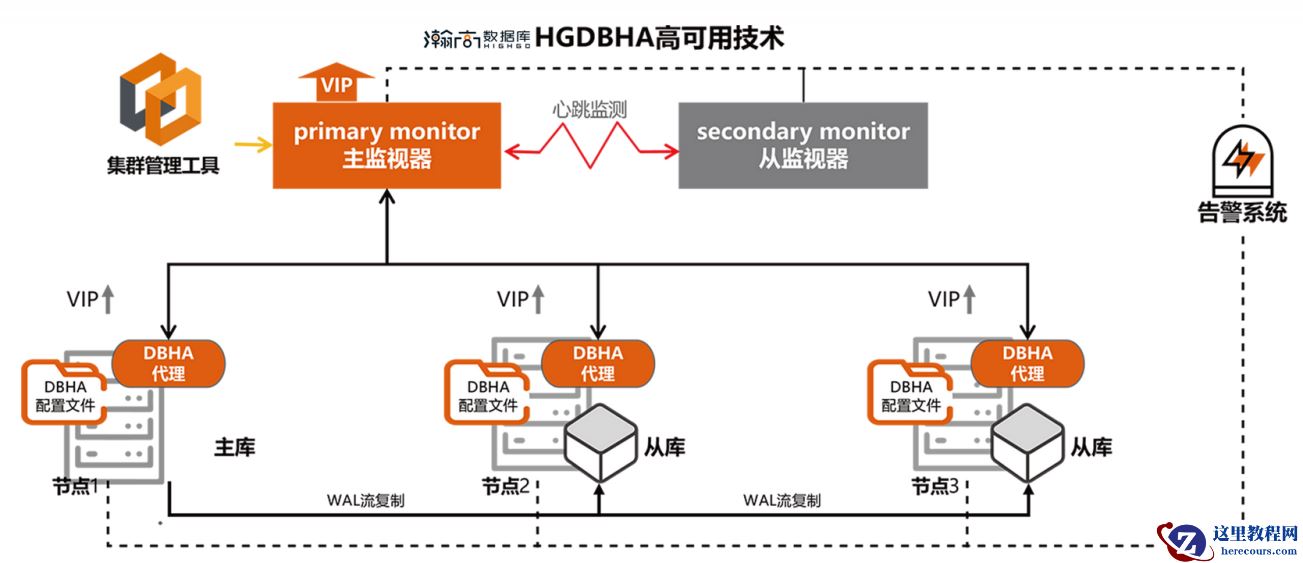
PostgreSQL 高可用架构通过“监控-检测-转移-恢复”的闭环设计,将数据库宕机的影响降至最低。其背后是流复制、分布式协调、智能选主等技术的深度融合,更是对业务连续性需求的精准回应。在实际部署中,需结合场景选择同步/异步复制模式,配置合理的监控告警,并定期演练故障恢复流程,方能筑牢数据安全的最后一道防线。






")





