背景

为什么会有双主这种架构?
大体上双主架构方案有两种玩法:
双主单写
双主双写
1. 双主单写(相对推荐)
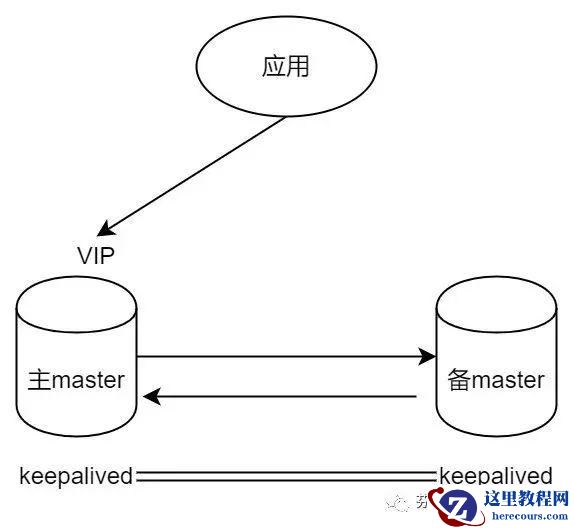
实际上,”keepalived + 双主”和”keepalived + 主从”的架构差异并不明显。如果你能确保在”双主”架构中只允许单点写入,这种架构和”keepalived + 主从”一样,是完全没有问题的。然而,”双主”架构的特性,也就是从库同时也是主库这一件事,可能带来一些问题。比如:
2.双主双写
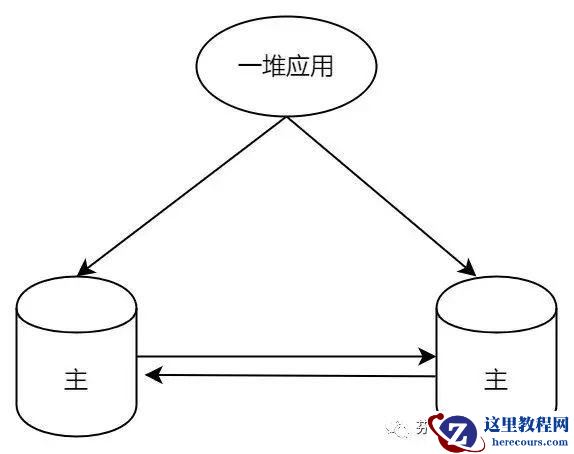
双主双写的架构方案就完全不能用吗,如何解决呢?
解决办法 1: 隔开自增键,按行写入(不推荐)
有人认为两个主库设置不一样的自增键可以解决:
auto_increment_offset = 1 # 主库为1,从库为2auto_increment_increment = 3 # 自增步长
解决办法 2: 按表或按库写入(相对推荐)
双活架构,由于复杂性,可能有一些方案会考虑跨机房之间的异步复制采用双向同步复制方案,只要规避好坑,严格地单元化拆分业务,我觉得可以接受。不在这篇文章讨论范围,我们只讨论本地高可用。
二、双主复制有可能导致复制回环
1.部署回环架构
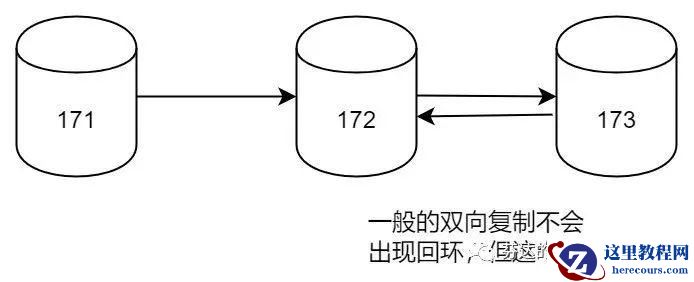
实验步骤(不感兴趣的,可以快速跳过,直接看结论):
[root@192- 168- 199- 175 playbooks] # pwd/usr/ local/dbops/mysql_ansible/playbooks
# vi ../inventory/hosts.ini
[dbops_mysql]
192.168.
199.171 ansible_user=root ansible_ssh_pass=
"'gta@2015'"
192.168.
199.172 ansible_user=root ansible_ssh_pass=
"'gta@2015'"
192.168.
199.173 ansible_user=root ansible_ssh_pass=
"'gta@2015'"
[root@192-
168-
199-
175 playbooks]
# vi vars/var_master_slave.yml
# vars loading order: common_config -> this file
master_ip:
192.168.
199.171
slave_ips:
-
192.168.
199.172
-
192.168.
199.173
sub_nets:
1%
[root@192-
168-
199-
175 playbooks]
# ansible-playbook master_slave.yml
# playbook会做一些校验通过后,要求您确认信息是否正确,然后你手工输入"confirm"后正式运行
使用 dbops 快速部署好生产级别的一主两从。
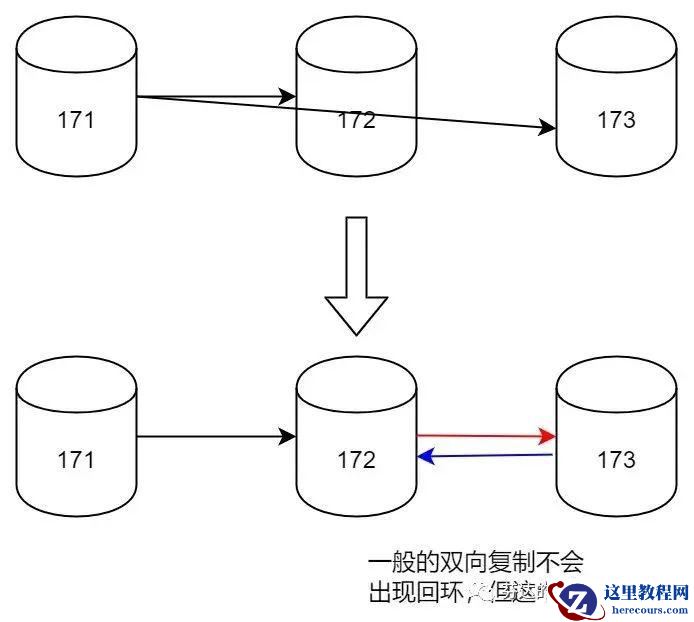
如下图,上面部分是目前部署出来的一主两从,需要修改为下面的架构,需要执行两次 change master to 语句即可。
首先,我需要在 dbops server 上查看复制账号的账号名和密码
# 在dbops server上查看复制账号的账号名和密码[root@192-168-199-175 playbooks]# cat common_config.yml |grep rplemysql_rple_user: replmysql_rple_password: Repl@8888
然后,我登录 172 服务器,执行 change master to 173,让 173 是主,172 是从,建立图中蓝色箭头的数据流向。
[root@192-168-199-172 ~]# su mysql[root@192-168-199-172 ~]# db3306 # dbops的默认设定,提供的管理员免密快捷登录数据库的方式mysql> CHANGE MASTER TO MASTER_HOST='192.168.199.173', MASTER_PORT=3306, MASTER_USER='repl', MASTER_PASSWORD='Repl@8888', MASTER_AUTO_POSITION=1 for channel 'master173';mysql> start slave;
由于 172 既是 171 的从,也是 173 的从,是一种多源复制的架构,所以 change master to 时要指定一个 channel 名,以区分两个复制链路。
接着,我使用相同的方法,登录 173,执行 change master to 172,让 172 是主,173 是从,建立图中
红色箭头的数据流向。
# su mysql# db3306 # dbops的默认设定,提供的管理员免密快捷登录数据库的方式mysql> stop slave;mysql> CHANGE MASTER TO MASTER_HOST='192.168.199.172', MASTER_PORT=3306, MASTER_USER='repl', MASTER_PASSWORD='Repl@8888', MASTER_AUTO_POSITION=1;mysql> start slave;
2.验证回环
架构我们部署好了,现在我们来模拟和验证复制回环。
现在 172 上,停掉它回放 173 的 sql 线程,让他只拷贝 binlog 但不回放 SQL。
mysql> stop slave sql_thread for channel 'master173';
登录 171,建个 fander 库。
[root@192-168-199-171 ~]# su mysql[root@192-168-199-171 ~]# db3306 # dbops的默认设定,提供的管理员免密快捷登录数据库的方式mysql> create database fander;
登录 172 和 173,都能看到 fander 库同步过来的。
mysql> show databases;+--------------------+| Database |+--------------------+| fander || information_schema || mysql || performance_schema || sys |+--------------------+5 rows in set (0.00 sec)
我们查看 172 上回放 173 方向同步过来的 relay log,能发现他确实把 create database fander 语句又回环过来了。GTID 编号为 ‘b0ae588e-0eb4-11ee-b23f-000c297b0a30:3’。
# 172[mysql@192-168-199-172 3306]$ pwd/database/mysql/log/relaylog/3306[mysql@192-168-199-172 3306]$ lltotal 24-rw-r----- 1 mysql mysql 204 Jun 19 23:20 relay-bin.000001-rw-r----- 1 mysql mysql 1090 Jun 19 23:53 relay-bin.000002-rw-r----- 1 mysql mysql 102 Jun 19 23:20 relay-bin.index-rw-r----- 1 mysql mysql 214 Jun 19 23:47 relay-bin-master173.000001-rw-r----- 1 mysql mysql 618 Jun 19 23:53 relay-bin-master173.000002-rw-r----- 1 mysql mysql 122 Jun 19 23:47 relay-bin-master173.index[mysql@192-168-199-172 3306]$ mysqlbinlog -vvv relay-bin-master173.000002 |grep fander#git编号: 'b0ae588e-0eb4-11ee-b23f-000c297b0a30:3'create database fander
请问这个 GTID ‘b0ae588e-0eb4-11ee-b23f-000c297b0a30:3’ 会重复应用,导致复制报错吗?
答案是不会。因为 GTID 的原理是, 他不会执行他标记已经执行过的 GTID,’b0ae588e-0eb4-11ee-b23f-000c297b0a30:3’ 在我启动 sql_thread for channel ‘master173’ 之前就已经标记执行过了,所以这个回环过来的 SQL 是不会执行的。
但如果我不是 GTID 模式的复制而是传统复制呢?那就会执行了!由于 database fander 已经存在,所以重复执行的结果就是复制报错,或者数据不一致了。
虽然在 GTID 模式下,不会重复执行 SQL,但存在一个问题,那就是回环问题。这导致了一些本不应该传输的 binlog 重复传输,使得网络流量翻倍。这是为什么呢?
3.出现回环的原因
要理解这个问题,我们需要先了解 MySQL 是如何防止复制回环的。其实,防止复制回环主要靠的是每个 MySQL 服务器都有的一个的 server_id。在复制过程中,每个二进制日志事件都被标记为产生该事件的 server_id。当复制服务器接收到新的二进制日志事件时,它会检查该事件的 server_id。如果 server_id 与复制服务器自身的 server_id 相同,那么复制服务器就知道这个事件是它自己生成的,因此会忽略它,不会拷贝它。就是通过这种方式,MySQL 成功地防止了复制回环的发生。
在本案例中,我们有三个 MySQL 服务器,假设他们的 server_id 分别为 171、172、173。
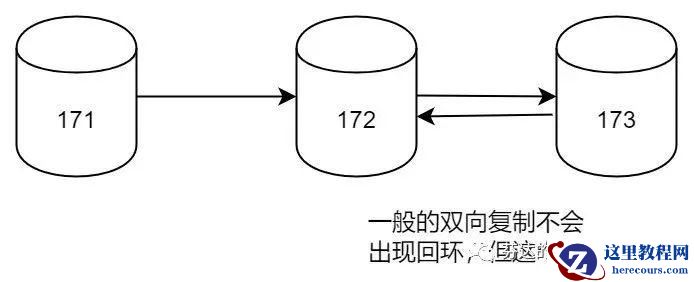
当服务器 171 生成了一个二进制日志事件(binlog event),这个事件被标记为 server_id 为 171。然后,这个事件被复制到了服务器 172,因为服务器 172 的 server_id 与事件的 server_id 不同,所以它接受了这个事件。然后,服务器 172 将这个事件传递给了服务器 173,服务器 173 也接受了这个事件,因为它的 server_id 与事件的 server_id 不同。
然而,问题出现在当服务器 173 将这个事件再传回给服务器 172 时。服务器 172 看到这个事件的 server_id 还是 171,与它自己的 server_id 依然不同,所以它依然会接受这个事件。好在我们使用了 GTID 模式,服务器 172 虽然拷贝了 binlog 过来,但会知道它已经应用过这个事件,因此它不会再次应用这个事件,从而避免了可能的数据不一致问题。所以,虽然事件被多次传输,但是使用 GTID 可以防止事件被多次应用,从而避免了数据不一致问题。





![[bug]MySQL 哈希扫描错误地应用日志导致主从中断](https://www.herecours.com/d/file/efpub/2026/01-01/20260301170647760313.jpg?x-oss-process=style/bb "[bug]MySQL 哈希扫描错误地应用日志导致主从中断")






