图解:
oracle
内存结构
 后台进程
smon、pmon、ckpt、dbwr、lgwr ...
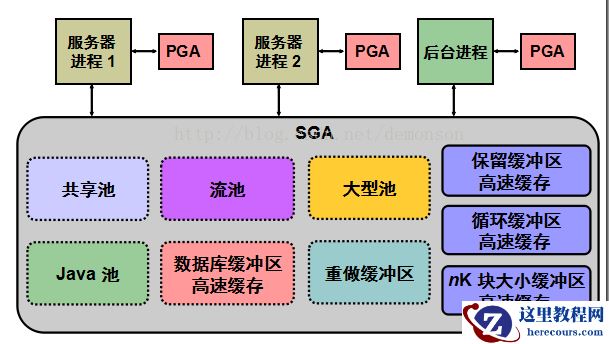
SGA(system global area)系统全局区
SGA是一组共享内存结构, 被所有的服务和后台进程所共享。当数据库实例启动时,系统全局区内存被自动分配。当数据库实例关闭时,SGA内存被回收。 SGA是占用内存最大的一个区域,同时也是影响
数据库
性能的重要因素。
视图参数:v$sga
后台进程
smon、pmon、ckpt、dbwr、lgwr ...
SGA(system global area)系统全局区
SGA是一组共享内存结构, 被所有的服务和后台进程所共享。当数据库实例启动时,系统全局区内存被自动分配。当数据库实例关闭时,SGA内存被回收。 SGA是占用内存最大的一个区域,同时也是影响
数据库
性能的重要因素。
视图参数:v$sga
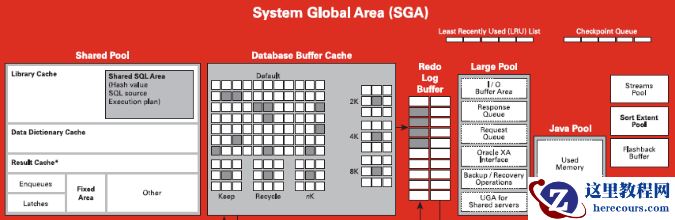
Fixed Size表示固定区域,存储SGA各个 组件的信息。不能修改大小。
Variable Size表示可变区域,比如共享池、java池、大池等。
Database Buffers表示数据库高速缓冲区。
Redo Buffers表示日志缓冲区。 shared pool (共享池) 用于存放SQL语句、PL/SQL代码、数据字典、资源锁和其他控制信息。它由初始化参数SHARED_POOL_SIZE控制其大小。
1、 数据字典缓存(data dictionary cache) :用于存储经常使用的数据字典信息。比如(表的定义、用户名、口令、权限、数据库的结构等)。Oracle运行过程中经常访问该缓存以便解析SQL语句,确定操作的对象是否存在,是否具有权限等。如果不在数据字典缓存中,服务器进程就从保存数据字典信息的数据文件中将其读入到数据字典缓存中。数据字典缓存中保存的是一条一条的记录(就像是内存中的数据库),而其他缓存区中保存的是数据块信息。
2、 库缓冲区(Library Cache): 库缓存的目的就是保存最近解析过的SQL语句、PL/SQL过程和包。这样一来,Oracle在执行一条SQL语句、一段PL/SQL 过程和包之前,首先在“库缓存”中搜索,如果查到它们已经解析过了,就利用“库缓存”中解析结果和执行计划来执行,而不必重新对它们进行解析,显著提高执行速度和工作效率。
ORACLE将每一条SQL语句分解为可共享、不可共享的两部分。
a) 共享SQL区:存储的是最近执行的SQL语句、解析后的语法树和优化后的执行计划。这样以后执行相同的SQL语句就直接利用在共享SQL区中的缓存信息,不必重复语法解析了。Oracle在执行一条新的SQL语句时,会为它在共享SQL区中分配空间,分配的大小取决于SQL语句的复杂度。如果共享SQL区中没有空闲空间,就利用LRU算法,释放被占用的空间。
b) 私用SQL区(共享模式时):存储的是在执行SQL语句时与每个会话或用户相关的私有信息。其他会话即使执行相同的SQL语句也不会使用这些信息。比如(绑定变量、环境和会话参数)。
3、 结果高速缓存:结果高速缓存包含 SQL 查询结果高速缓存和 PL/SQL 函数结果高速缓存。此高速缓存用于存储 SQL 查询或 PL/SQL 函数的结果,以加快其将来的执行速度。
4、 锁与其他控制结构:存储ORACLE例程内部操作所需的信息。比如(各种锁、闩、寄存器值)。
块缓冲区(Database buffer cache)
数据高速缓冲区(Database Buffer Cache):用于存放从数据文件读取的数据块,由初始化参数DB_CACHE_SIZE决定。
工作原理和过程是 LRU(最近最少使用 Least Recently Used )。查询时,Oracle会先把从磁盘读取的数据放入内存供所有用户共享,以后再查询相关数据时不用再次读取磁盘。插入和更新时,Oracle会先在该区中缓存数据,之后批量写到硬盘中。通过块缓冲区,Oracle可以通过内存缓存提高磁盘的I/O性能(注:磁盘I/O的速率是毫米级的,而内存I/O的速率为纳秒级)
数据高速缓存块由许多大小相等的缓存块组成,这些缓存块的大小和OS块大小相同。 这些缓存块分为3大类
Oracle 通过 2 个列表(DIRTY、LRU)来管理缓存块
1、DIRTY 列表中保存已经被修改但还没有被写入到数据文件中的脏缓存块。
2、LRU列表中保存所有的缓存块(还没有被移动到DIRTY列表中的脏缓存块、空闲缓存块、命中缓存块)。当某个缓存块被访问后,该缓存块就被移动到LRU列表的头部,其他缓存块就向LRU列表的尾部移动。放在最尾部的缓存块就最先被移出LRU列表。
数据高速缓存的工作原理过程是:
A、ORACLE在将数据文件中的数据块复制到数据高速缓存中之前,先在数据高速缓存中找空闲缓存块,以便容纳该数据块。Oracle 将从LRU列表的尾部开始搜索,直到找到所需的空闲缓存块为止。
B、如果先搜索到的是脏缓存块,将该脏缓存块移动到DIRTY列表中,然后继续搜索。如果搜索到的是空闲缓存块,则将数据块写入,然后将该缓存块移动到DIRTY列表的头部。
C、如果能够搜索到足够的空闲缓存块,就将所有的数据块写入到对应的空闲缓存块中。则搜索写入过程结束。
D、如果没有搜索到足够的空闲缓存块,则ORACLE就先停止搜索,而是激活DBWn进程,开始将DIRTY列表中的脏缓存块写入到数据文件中。
E、已经被写入到数据文件中的脏缓存块将变成空闲缓存块,并被放入到LRU列表中。执行完成这个工作后,再重新开始搜索,直到找到足够的空闲缓存块为止。
这里可以看出,如果你的高速缓冲区很小的,不停地写写,造成很大I/O开销。
块缓冲区可以配置1、2或3个缓冲池,默认只有一个
原来只有一个默认池,所有数据都在这里缓存。这样会产生一个问题:大量很少重用的数据会把需重用的数据“挤出”缓冲区,造成磁盘I/O增加,运行速度下降。后来分出了保持池和回收池根据是否经常重用来分别缓存数据。这三部分内存池需要手动确定大小,并且之间没有共享。例如:保持池中已经满了,而回收池中还有大量空闲内存,这时回收池的内存不会分配给保持池,这些池一般被视为一种非常精细的低级调优设备,只有所有其他调优手段大多用过之后才应考虑使用。
在9i之前,数据缓冲区的大小是由DB_BLOCK_BUFFER确定,之后的版本中,是由参数DB_CACHE_SIZE及DB_nK_CACHE_SIZE确定。不同的表空间可以使用不同的块大小,在创建表空间中加入参数BLOCKSIZE指定该表空间数据块的大小,如果指定的是2k,则对应的缓冲区大小为DB_2K_CACHE_SIZE参数的值,如果指定的是4k,则对应的缓冲区大小为DB_4K_CACHE_SIZE参数的值,以此类推。如果不指定BLOCKSIZE,则默认为参数DB_BLOCK_SIZE的值,对应的缓冲区大小是DB_CACHE_SIZE的值
重做日志缓冲区(Redo log buffer)
用于存放日志条目,日志条目就是记录对数据的改变。当这块区域用光时,后台进程LGWR把日志条目写到磁盘上的联机日志文件中。它由初始化参数log_buffer决定大小。同样的道理下,日志缓冲区应该稍微大点,特别是有长时间运行的事务的时候,可以大量减少I/O。
数据写到重做日志文件之前在这里缓存,在以下情况中触发:
- 每隔3秒
- 缓存达到1MB或1/3满时
- 用户提交时
- 缓冲区的数据写入磁盘前
大池(Large pool)
大池由初始化参数LARGE_POOL_SIZE确定大小,可以使用ALTER SYSTEM语句来动态改变大池的大小,是可选项,DBA可以根据实际业务需要来决定是否在SGA区中创建大池。如果没有创建大池,则需要大量内存空间的操作将占用共享池的内存, 将对SHARED POOL造成一定的性能影响,而LARGE POOL是起着这种功能隔离作用的一块区域。
ORACLE 需要大量内存的操作有:
A、数据库备份和恢复,如RMAN某些情况下用于磁盘IO缓冲区
B、具有大量排序操作的SQL语句
C、并行化的数据库操作,存放进程间的消息缓冲区
D、共享服务器模式下UGA在大池中分配(如果设置了大池)
Java池(Java pool)
用于支持在数据库中运行java代码,一般由java_pool_size控制
流池(Stream pool)
加强对流的支持,一般由stream_pool_size控制。流池(或者如果没有配置流池,则是共享池中至多10%的空间)会用于缓存流进程在数据库间移动/复制数据时使用的队列消息 PGA(Process global area)进程全局区 一个PGA是一块独占内存区域,Oracle进程以专有的方式用它来存放数据和控制信息。当Oracle进程启动时,PGA也就由Oracle数据库创建了。当用户进程连接到数据库并创建一个对应的会话时,Oracle服务进程会为这个用户专门设置一个 PGA 区,用来存储这个用户会话的相关内容。当这个用户会话终止时,系统会自动释放这个 PGA 区所占用的内存。 PGA主要包含排序区、会话区、堆栈区以及游标区4个部分。 排序区: 当用户需要对某些数据进行排序时,数据库系统会将需要排序的数据保存到PGA 程 序缓存区中的一个排序区内。然后再在这个排序区内对这些数据进行排序。如需要排序的数据有2M,那么排序区内必须至少要有2M的空间来容纳这些数据。然后 排序过程中又需要有2M的空间来保存排序后的数据。 设置排序区大小的参数是: SORT_AREA_SIZE 会话区: 保存着用户的权限等重要信息(权限、角色、性能统计等信息), 这个会话区一般都是由数据库进行自我维护的,系统管理员不用干预。 堆栈区: 保存变量信息(保存绑定变量) 为了提高SQL语句的重用性(效率),会在语句中使用绑定变量。用户只需要输入不同的变量 值,就可以满足不同的查询需求。不需要多次解析,只需要使用库缓存区之前解析过的执行计划就行,节省了解析时间,提高了性能。 游标区: 游标区是一个动态的区域。当用户执行游标语句时,系统就会在这个游标区内创建一个区域。当关闭游标时,这个区域就会被释放。这创建与释放,需要占用一定的系统资源,花费一定的时间。 在Oracle数据库中,还可以通过限制游标的数量来提高数据库的性能。 设置游标的参数:OPEN_CURSORS UGA(User global area)用户全局区 专用服务模式:进程与会话是一对一的关系,UGA属于PGA; 共享服务模式:进程与会话是一对多的关系,此时UGA不再属于PGA,而是在large pool中分配; large pool分配失败或者是未配置large pool,UGA则是从shared pool中分配;
后台进程
后台进程是数据库和操作系统进行交互的通道,oracle根据ORACLE_SID来寻找参数文件,启动实例。
smon: 实例恢复,合并空闲碎片空间,回收临时段;
pmon: 用户进程意外终止时处理事务,释放锁及其他被占用的资源;
ckpt: 协调数据文件、控制文件、重做日志文件,将SCN写入到控制文件和数据文件头部,促使DBWR和LGWR执行;
dbwr: 将buffer cache 中的脏数据块写入到磁盘中(数据文件中);
lgwr: 将redo log buffer中的数据写入到重做日志文件;





")
")

")



